如果你只想体验下 Gemma 7b 的问答效果,可以通过「方式一」给出的地址访问 Huggingface Chat,方式二为本地部署 Gemma,适合更进一步的测试和使用。
Gemma 2b 和 7b 区别在于模型的尺寸,2b 有 20+亿参数,7b 约为 70+亿参数,实际体验下来,7b 相比 2b 好很多。
我的测试环境是 Apple M2 16 GB,跑 7b 没压力,如果你的内存大些,可以尝试跑 7b 的完整版本 gemma:7b-instruct-fp16,17GB 大小
方式一:使用 Huggingface 提供的在线工具
地址:https://huggingface.co/chat?model=google/gemma-7b-it
再问一个:
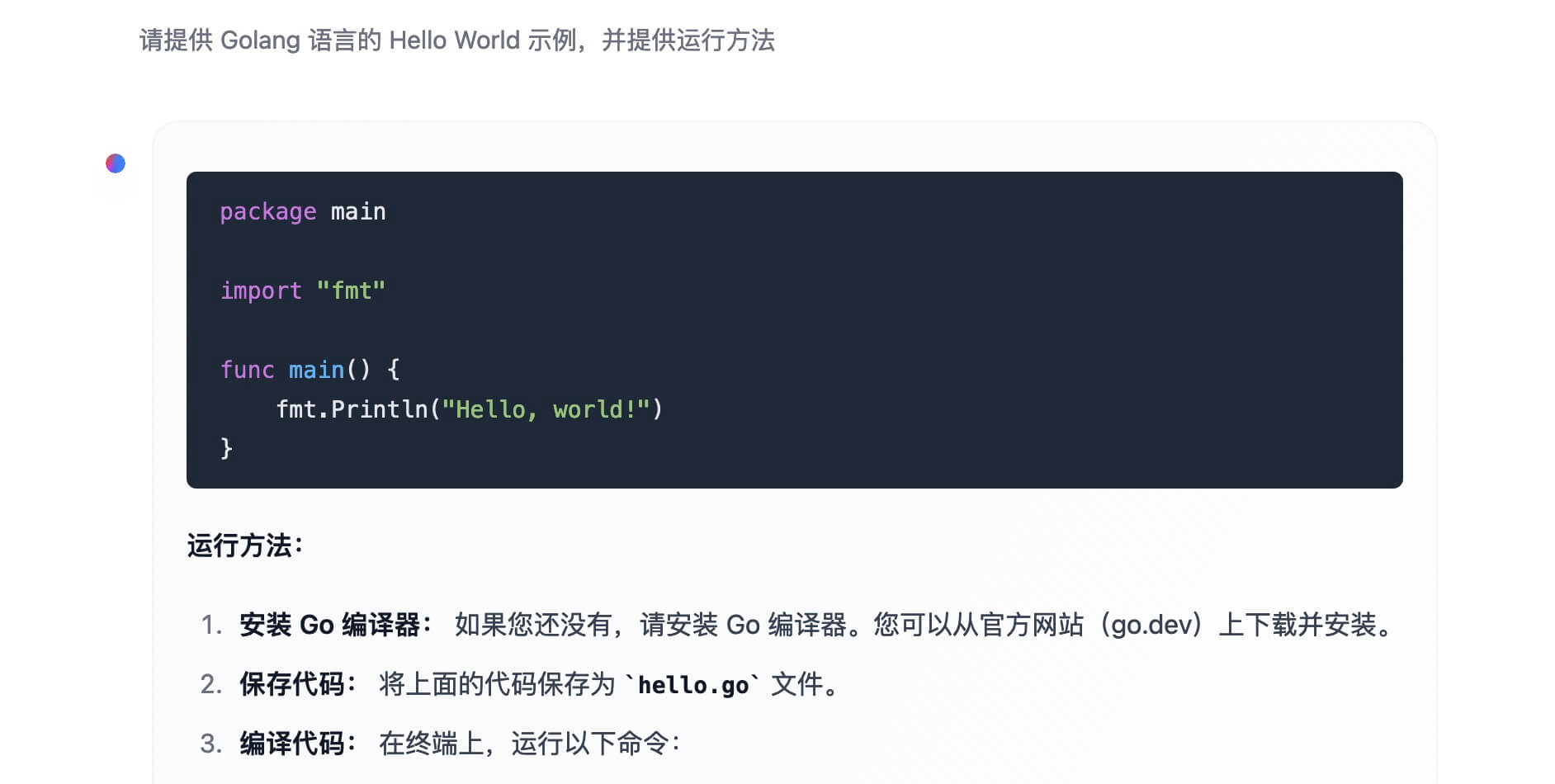
方式二:本地 Ollama + Chat 客户端
在自己的电脑运行 Gemma 模型,推荐使用 Ollama
下载地址:https://ollama.com/download
安装后,就是右侧的那个小羊驼图标

接下来运行模型,打开终端,运行模型,首次运行会自动下载模型,根据网络环境可能会比较久
$ ollama run gemma:7b
下载后即可在命令行进行「交互式」提问,亲测 Gemma 7b 在 MacOS 上运行很快

使用 --verbose 参数可以输出更多的信息

另外 Gemma 占用内存情况如下
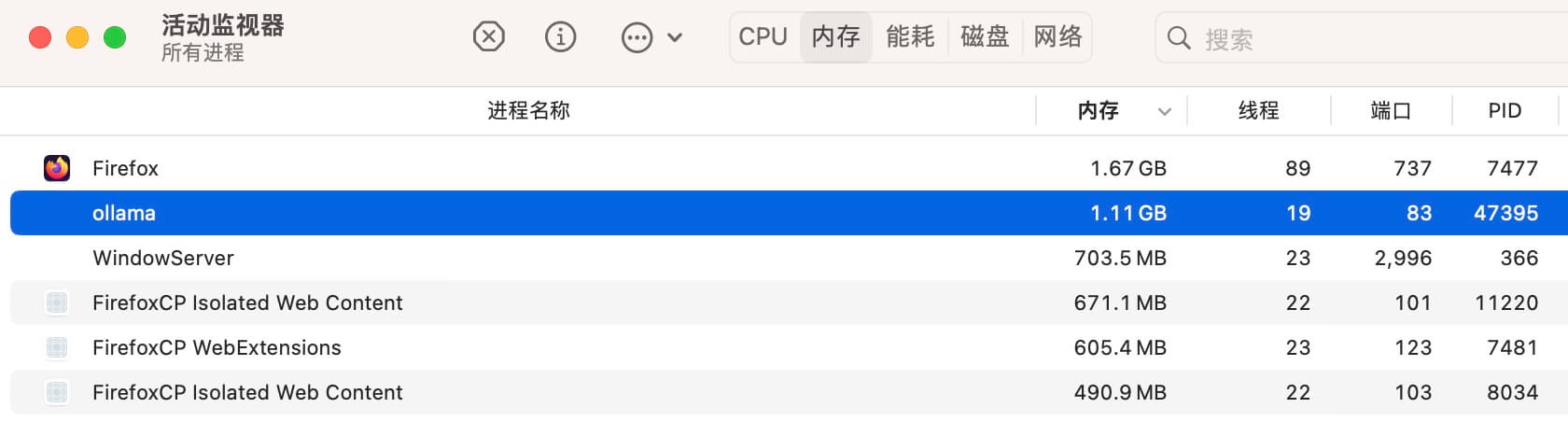
使用本地客户端
如果你参照了「方式二」部署本地服务,可以推荐使用 Chat 客户端来使用,交互会更加友好。
推荐 ChatBox 和 NextChat 客户端
首先要了解,Ollama 服务可以通过 API 接口使用模型,地址为 http://localhost:11434
访问 http://localhost:11434/api/tags 可以得到模型名称及信息。
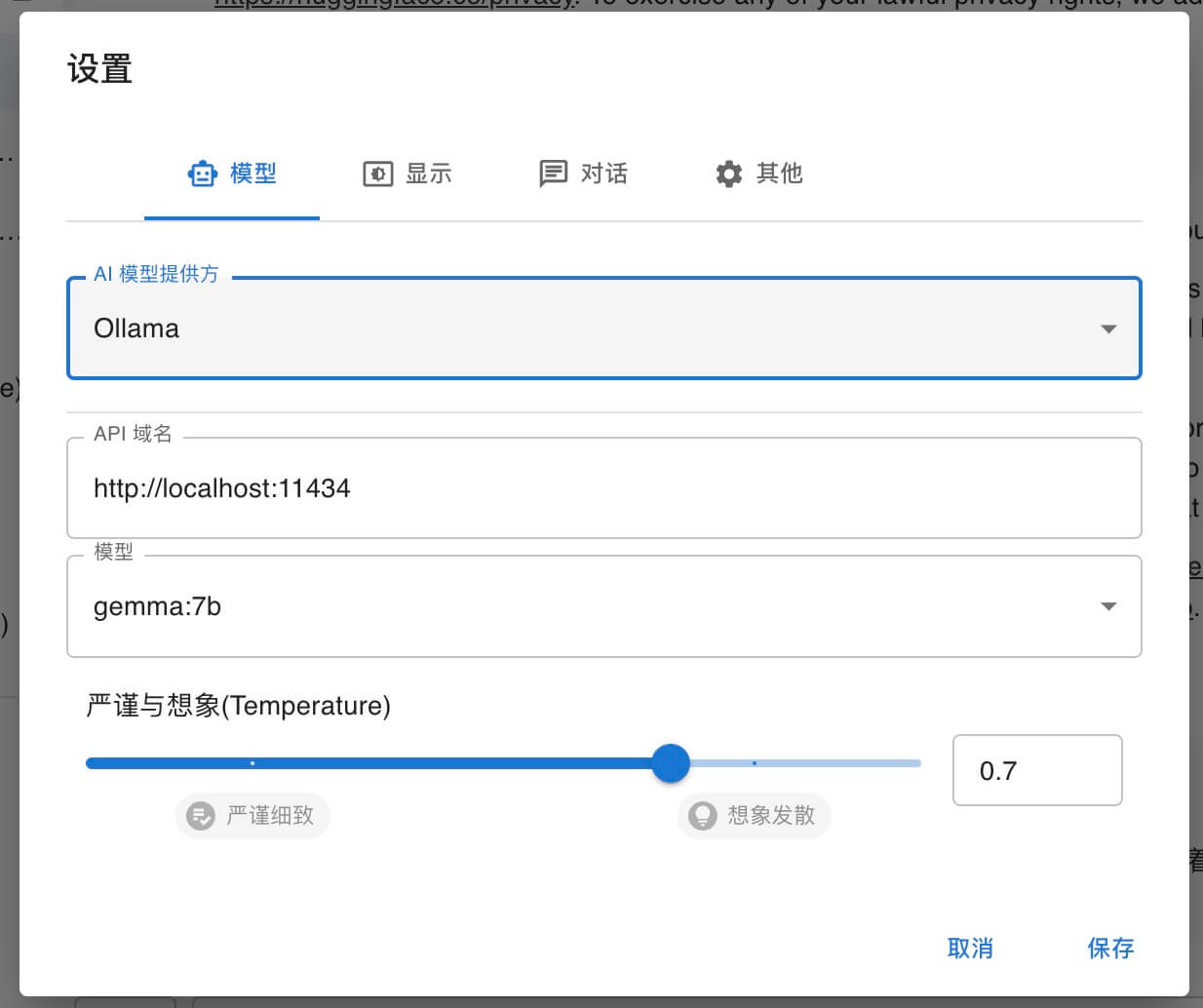
ChatBox 使用 Gemma:7b 模型配置
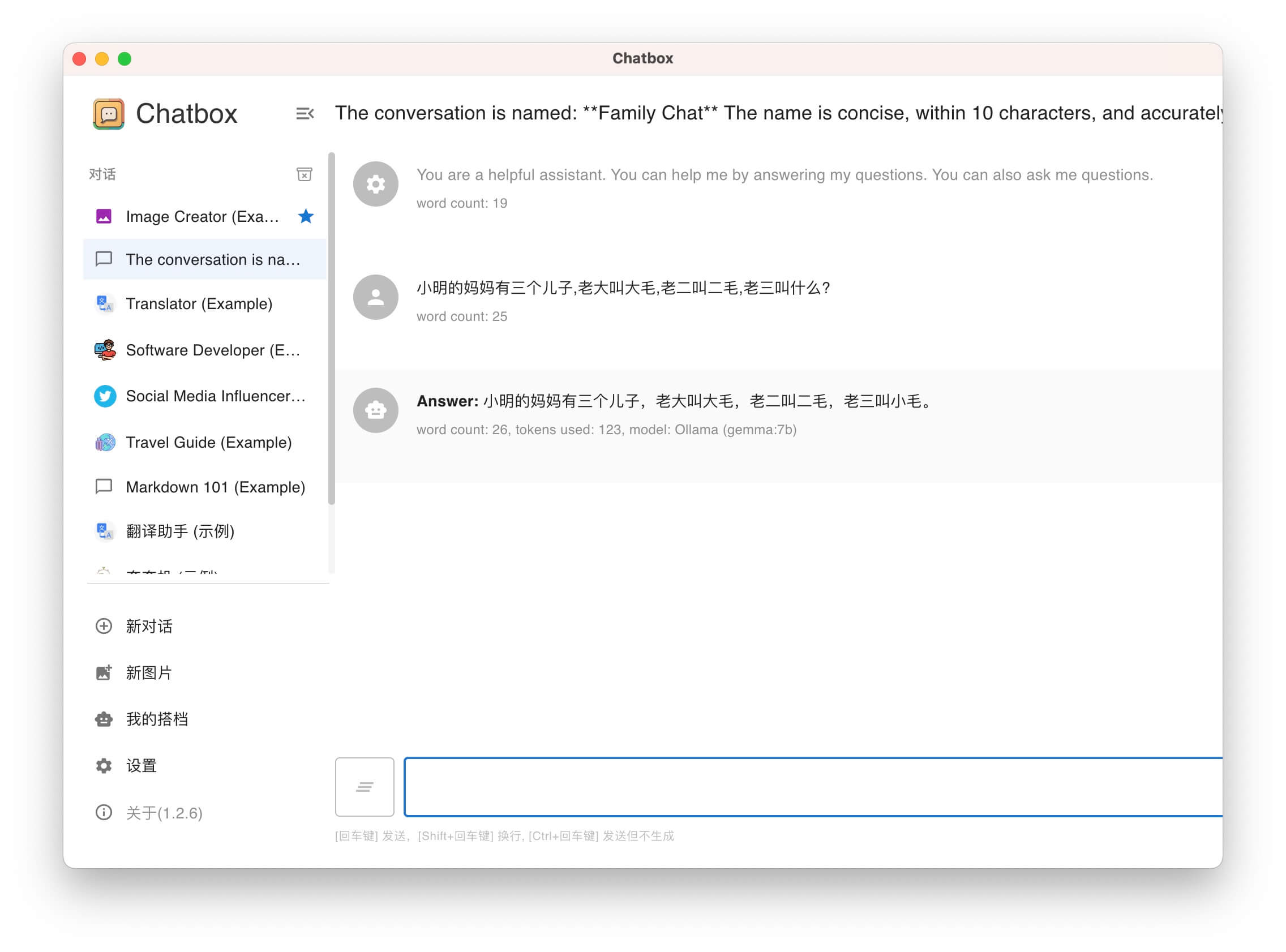
使用效果:
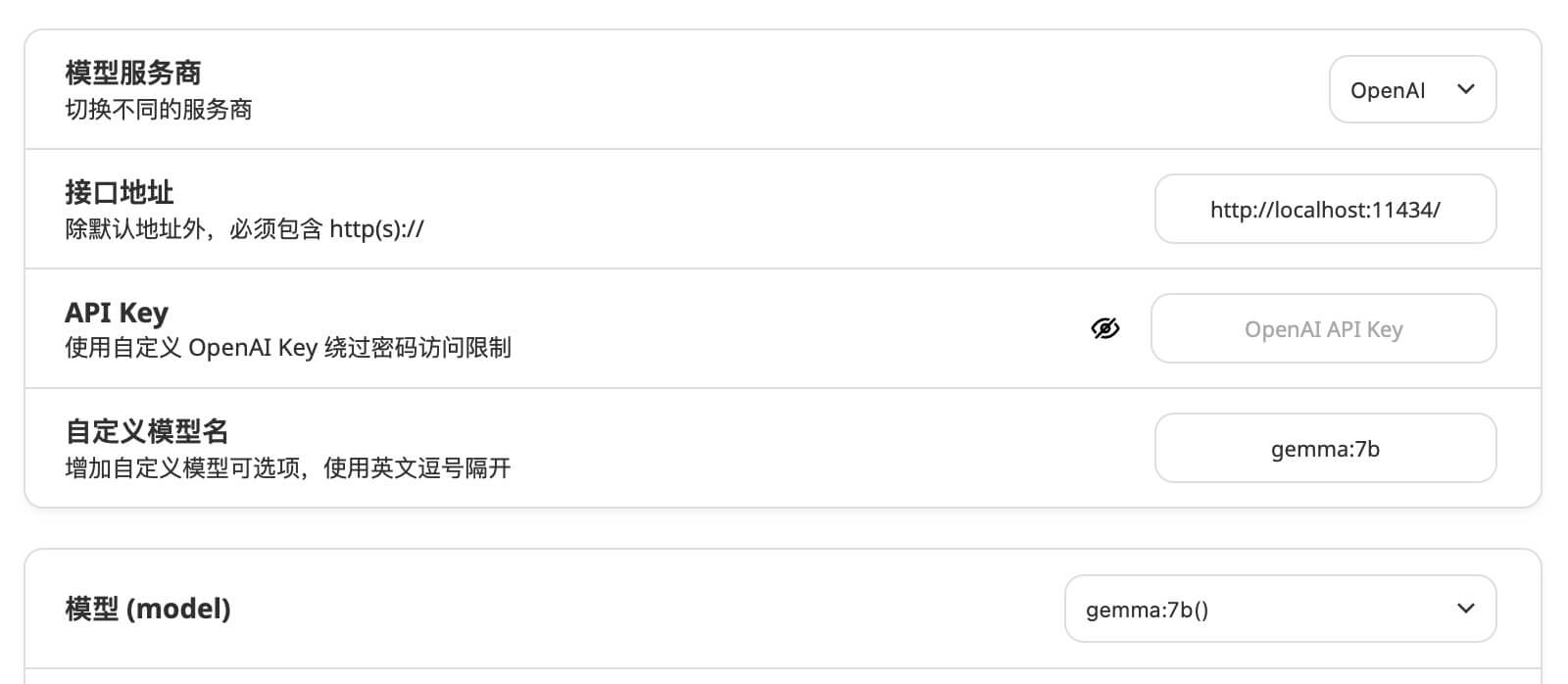
NextChat 使用 Gemma:7b 模型配置
NextChat 即 ChatGPT-Next-Web,是基于 Web 应用打包的,所以会存在跨域问题。这里需要多设置一步。
$ launchctl setenv OLLAMA_ORIGINS "*"
$ launchctl setenv OLLAMA_HOST "0.0.0.0"前文将 Ollama 作为 macOS 应用进行安装,环境变量需如上设置,而后重启 Ollama
If Ollama is run as a macOS application, environment variables should be set using launchctl: 1. For each environment variable, call launchctl setenv. 2. Restart Ollama application.
设置使用 Gemma
使用效果: