概要
前一阵尝试了解 mp4 视频文件的格式,网上有不少资料介绍 mp4 的结构以及各字段所代表的含义,使用 Mp4 Explorer 工具加载 mp4 视频来查看它的结构及基本信息,作为 Coder,我更感兴趣的是如何从视频文件中解析出信息,在这之前,我还没有用程序来解析过二进制文件,本次实践,对解析二进制文件有了更清晰的感受。
尝试使用 Python
按照我的思路,如果能找到一个用来解析 mp4 的 Python 示例,那么我阅读一下源代码,对如何解析 mp4 元信息就会清晰明了了,首先搜索到一个名为 pymp4 的模块,我尝试运行了一下,发现 Python3 版本不支持,并且有一段时间没有更新,而换用 Python2 来执行,又有其它的问题,翻看了一会儿代码,不想修修补补,于是决定尝试用别的语言搜搜,说不定有惊喜。
接下来我搜索了 Rust 语言,如果网上没有开源的 Rust 实现的小 DEMO 供我阅读,我会换用 Node.js 再找找,幸运的是,我找到一个叫 rust-mp4 的模块,下载运行后,它很快解析出了 mp4 的视频信息。
阅读 rust-mp4 源代码
作为一个 Rust 初学者,只掌握基础语法的情况下,阅读这个示例程序真的很舒服,代码的可读性很好,作者是国人,十分感谢。
地址:https://github.com/OpenAnsible/rust-mp4
从入口开始
cargo run --example parse使用 cargo 运行,在 example 目录下有一个名为 parse.rs 的文件,这里就是入口了。
extern crate mp4;
fn main (){
mp4::parse_file("test.mp4");
}在 src/lib.rs 文件中,接下来就看 parse_file 是如何解析 mp4 文件。
pub fn parse_file(filename: &str) -> Result<Mp4File, &'static str>{
let mut mp4 = Mp4File::new(filename).unwrap();
mp4.parse();
for atom in mp4.atoms() {
println!("Atom: \n\t{:?}", atom);
}
Ok(mp4)
}
作者定义了一个结构体来存储 mp4 的基础信息,包括文件大小,读取的指针偏移,以及用于保存解析到数据的动态数组。
#[derive(Debug)]
pub struct Mp4File {
file : File,
file_size: u64,
offset : u64,
atoms : Vec<atom::Atom>
}同时,为结构体实现了不少的方法用来对实例进行操作。
impl Mp4File {
pub fn new(filename: &str) -> Result<Self, &'static str> {
// ...
}
pub fn file(&self) -> &File {
&self.file
}
pub fn file_size(&self) -> u64 {
self.file_size
}
pub fn offset(&self) -> u64 {
self.offset
}
pub fn offset_inc(&mut self, num: u64) -> u64 {
self.offset += num;
self.offset
}
pub fn atoms(&self) -> &Vec<atom::Atom> {
&self.atoms
}
pub fn parse(&mut self) {
let atoms = atom::Atom::parse_children(self);
self.atoms = atoms;
}
} 再接下来,到 mp4.parse();,继而调用 atom::Atom::parse_children(self) 来开始进行解析。
Atom 是一个枚举类型,像 mp4 中的 ftyp,Moov等各样的盒子都统一存放在了 Atom 枚举类型中。
#[derive(Debug, Clone)]
pub enum Atom {
ftyp(Ftyp),
free(Free),
moov(Moov),
mvhd(Mvhd),
...
// Meco
meco(Meco),
mere(Mere),
ignore(Ignore),
unrecognized(Unrecognized)
}回到 parse_children() 方法
pub fn parse_children(f: &mut Mp4File) -> Vec<Atom> {
let mut atoms: Vec<Atom> = Vec::new();
loop {
if f.offset() == f.file_size() {
break;
}
match Atom::parse(f) {
Ok(atom) => {
atoms.push(atom);
},
Err(e) => {
println!("[ERROR] ATOM parse error ({:?})", e);
break;
}
}
}
atoms
}
保存文件信息的结构体实例被传进来后,首先初始化了动态数据保存数据,判断结构体的 offset 偏移是不是与文件大小相等(因为每次读取一些数据后,指针都会根据数据块大小进行移动,当指针偏移等于文件大小时,说明文件已经被遍历一遍了)
借助 Atom::parse() 方法来进行数据解析,但是解析之前,需要知道这块数据是什么类型的,不同类型的盒子,存储内容不同,它们占的字节数就不同,所以需要首先确定即将解析的数据块是什么类型的。
pub fn parse(f: &mut Mp4File) -> Result<Self, &'static str> {
let mut header = Header::parse(f).unwrap();
println!("DO: \n{:?}", header);
...
}Header 是一个结构体,使用它来解析判断盒子的类型。
#[derive(Debug, Clone)]
pub struct Header {
size : u32,
kind : Kind, // atom type
// Optional
largesize : Option<u64>,
usertype : Option<[u8; 16]>,
version : Option<u8>,
flags : Option<[u8; 3]>, // 24 Bits
// 自定义抽象
atom_size : u64, // atom size , include header and data.
header_size: u64, // atom header size, not include data size.
data_size : u64, // atom data size , not include header size.
offset : u64, // file offset.
}size 是一个 32 位的数据类型,用于存储这块数据总共占用多少字节,kind 存储的是这块数据的类型。
这两个数据是在二进制文件中真实存在的,如果没有 size,那么二进制文件也就没办法区分不同的数据块(header + data)了,kind 也是必要的,因为它代表着这块数据的类型,决定着除去头部以外,data 数据如何来解析。
先回到代码 Header::parse() 方法。
impl Header {
pub fn parse(f: &mut Mp4File) -> Result<Header, &'static str>{
let curr_offset = f.offset();
let size: u32 = f.read_u32().unwrap();
let kind_bytes: [u8; 4] = [
f.read_u8().unwrap(), f.read_u8().unwrap(),
f.read_u8().unwrap(), f.read_u8().unwrap(),
];
let kind = Kind::from_bytes(&kind_bytes).unwrap();
...
}f.read_u32() 使用结构体方法,从文件中读取了 32 bit 的数据。8位代表一个字节,也就是说从文件中读取了四个字节,之后的 kind,它也是占用了 32bit 的大小,通过封装好的 Kind:from_bytes()方法,就可以把这些数据转换成 str 类型了。
添加 println!("{}, {:?}", &size, &kind);
尝试打印一下 size 和kind
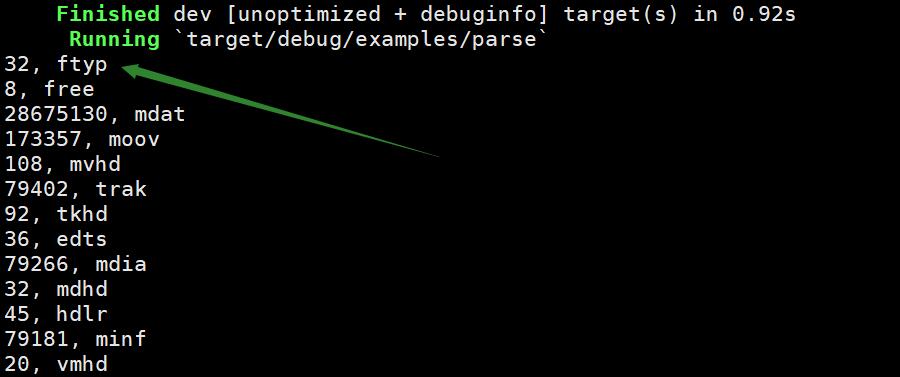
以第一行为例,32 代表 ftyp 类型块占用的字节数为 32 字节,type 类型刚刚看代码也知道它占了四字节,那么由此可知,Header 占用了 8 字节,剩下的 24 字节存储的为数据。
此时打开 Hex Editor Neo 就再好不过了。
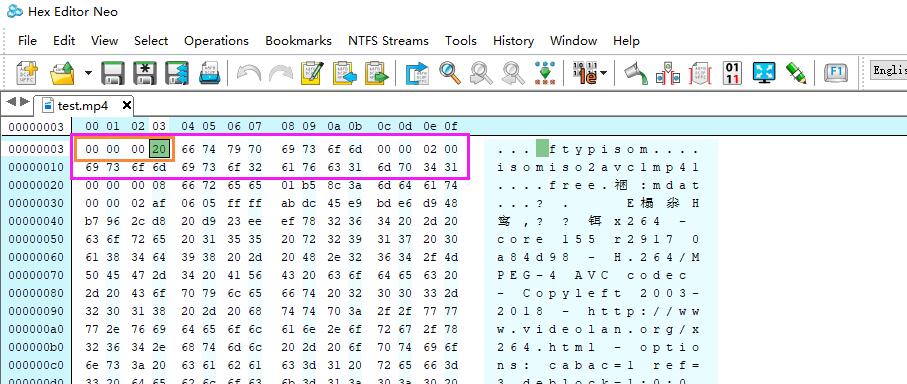
根据刚刚从代码获得的信息,来对照着看一下二进制文件编辑器上展示的内容,上面的数据都是十六进制展示的,8bit 代表一个字节,那么 size 当时读取了 32 位也就是 4 字节,因为 4bit 可以用来表示一个十六进制数(0000 -> 0, 1111 -> F),那么一个字节 8bit 可以存储两位的十六进制数,所以编辑器上的“00”代表一个字节,我们想要看的 size 数据 4 个字节,即为图中橘色框内的 “00 00 00 20”,不要忘记它是十六进制数,十六进制的 20 即为十进制的 32,代表这个类型块有32字节,编辑器上一行展示 16 字节,紫色框内的数据就是这个类型盒子的大小(包含头和数据部分)。
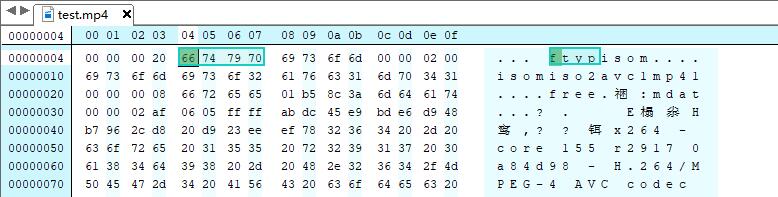
再看后边紧跟着的四个字节,程序中是按 8bit 来读取的,每 8bit 可以转换为一个字符。
根据 ASCII 表,对照可知,“66 74 79 70” 对应着字符串 “ftyp”,编辑器已经在右侧展示出来了。
size 和 type 这重要的信息,代码和HEX编辑器的内容对上了~
从这也可以看出,为什么所有的类型要都是 4 个字符,是 “ftyp” 而不是 “ftype”,因为作为关键的头信息结构内的数据,默认就这么大,它要是不定长,那么就无法根据 size -8字节 来得出数据块的大小了。
(PS:size 有值为1的时候,毕竟大文件,有的数据块太大,四个字节是无法存储的,这时需要设置size值为1,代表接下来 type 之后的 8 个字节用来表示 size 大小)
回到代码,通过 Header::parse()得知了这个类型块的类型,此处为 “ftyp”
接下来到了对具体类型,具体数据解析的时候了
Kind::ftyp => Ok(Atom::ftyp(Ftyp::parse(f, header).unwrap()))来到 src/atom/ftyp.rs 文件
pub struct Ftyp {
header: Header,
major_brand : FileType,
minor_version: u32,
compatible_brands: Vec<FileType>
}定义了 Ftyp 结构体,可以看到, header 就是刚才看到的通用头部结构体实例保存的头部信息,major 保存着当前mp4文件的类别,比如 ISO(avc1,iso2,isom,mp21,mp41),Apple(qt,m4b,m4p,m4a,m4v,m4vh,m4vp),Adobe(f4v,f4p,f4a,f4b),3GPP/GSM(mmp4)
pub fn parse(f: &mut Mp4File, header: Header) -> Result<Self, &'static str>{
let major_brand = Ftyp::parse_filetype(f).unwrap();
let minor_version = f.read_u32().unwrap();
let mut compatible_brands: Vec<FileType> = Vec::new();
let mut idx = (header.data_size - 8) / 4;
while idx > 0 {
compatible_brands.push(Ftyp::parse_filetype(f).unwrap());
idx -= 1;
}
f.offset_inc(header.data_size);
Ok(Ftyp{
header: header,
major_brand: major_brand,
minor_version: minor_version,
compatible_brands: compatible_brands
})
}minor 次要版本,是用来进行一些说明及相当于版本号的作用,major 是相同的,那么不会因为 minor 不同而不兼容。比如同为 mp42,不论 minor 是 1 还是 30,只要播放器说明其支持 mp42,那么解析就不会出现问题。
compatible_brands 兼容品牌,保存着兼容其它 major 的列表。
看代码可知 header.data_size - 8这里,ftyp 数据块,除掉 4 字节的 major,以及 4 字节的 minor,剩下的即为兼容品牌列表。
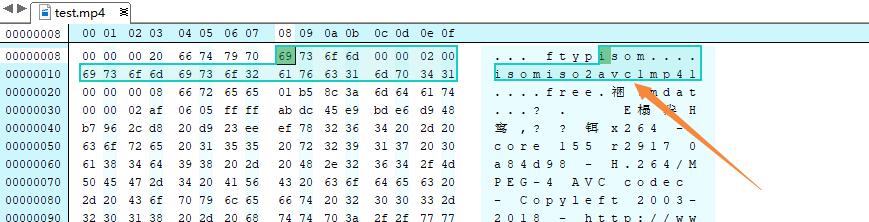
再到 hex 编辑器查看,剩下的 24 字节为 ftyp 的数据段,前四个字节是 major,即“isom”,之后的4个字节为“00 00 02 00”,它们何在一起表示 minor,即二进制的 “00000000 00000000 00000010 00000000” ,十进制的 512。
再之后是兼容列表,从右侧可以看到是“isom”,“iso2”,“avc1”,“mp41”。
到这里,已经完整的解析了一个盒子(ftyp)保存的信息,接下来就是循环,把所有的数据遍历完成,mp4 的信息就都获取出来了。
这个时候,再使用 Mp4 Explorer 来打开 mp4 文件查看一下
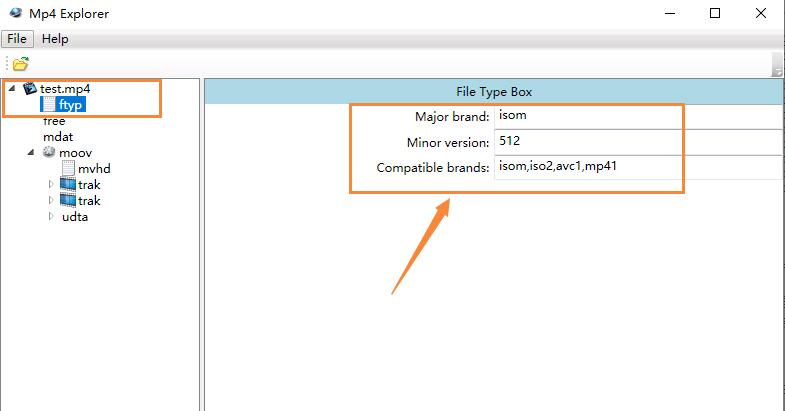
Mp4 Explorer 所解析的信息已不再神秘。
通过阅读 Rust 解析 mp4 文件信息的代码,了解了二进制文件解析的思路和实现细节,同时也更直观的了解了 mp4 文件为什么通过浏览器播放时,大部分要缓冲完才能进行拖动,因为视频信息分散在文件的各个地方,要全遍历一遍才能解析出mp4所有的信息。
我想我会抽时间把代码完整的看完,希望不久后自己写的 Rust 代码也能封装的良好,清晰易懂 (ง •_•)ง
这里有关于 MP4 格式详细说明:
https://blog.csdn.net/yefengzhichen/article/details/85562733