使用 Python 脚本从只读 Redis 实例中 SCAN 出符合标准的 KEY,在可写库更新其 TTL 时间,修复 KEY 未设置 TTL 过期时间问题,在这个过程中,监控报警,接口出现大量报错,同时发现 Redis 内存上涨。
内存上涨现象分析
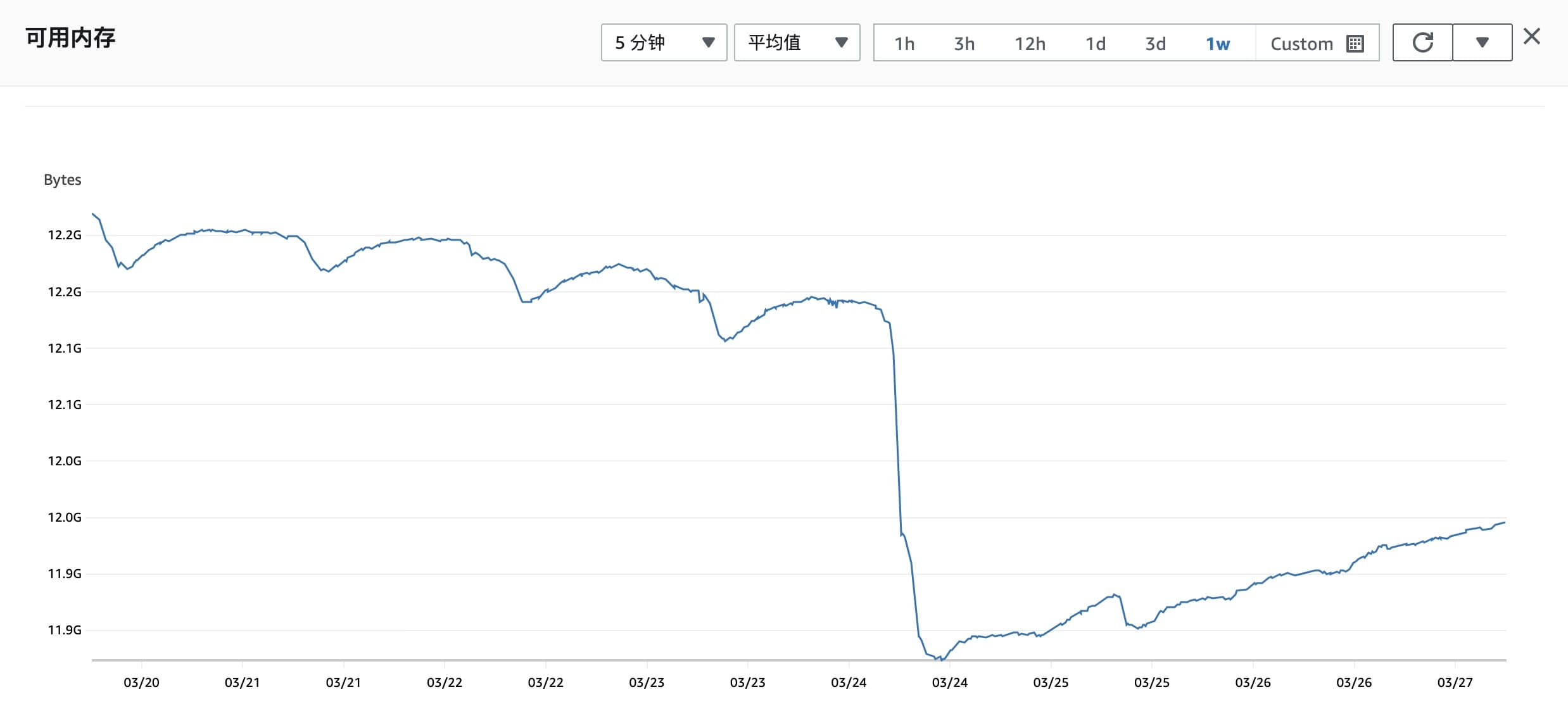
24 日可用内存减少
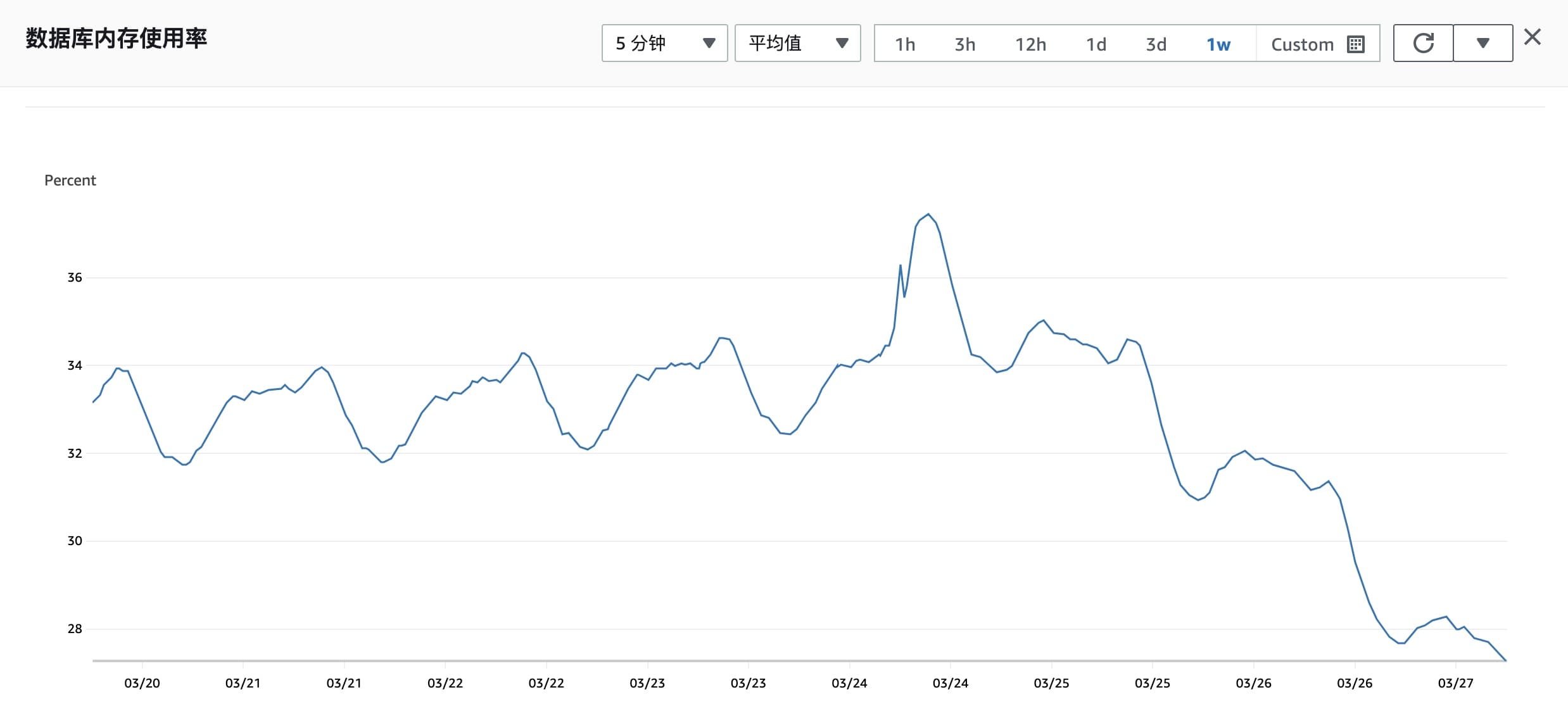
24 日内存使用率上涨
执行脚本前, 15:30 左右
# Keyspace(db0 数据库 keys 为总数量,expires 为带过期时间的 keys 数量)
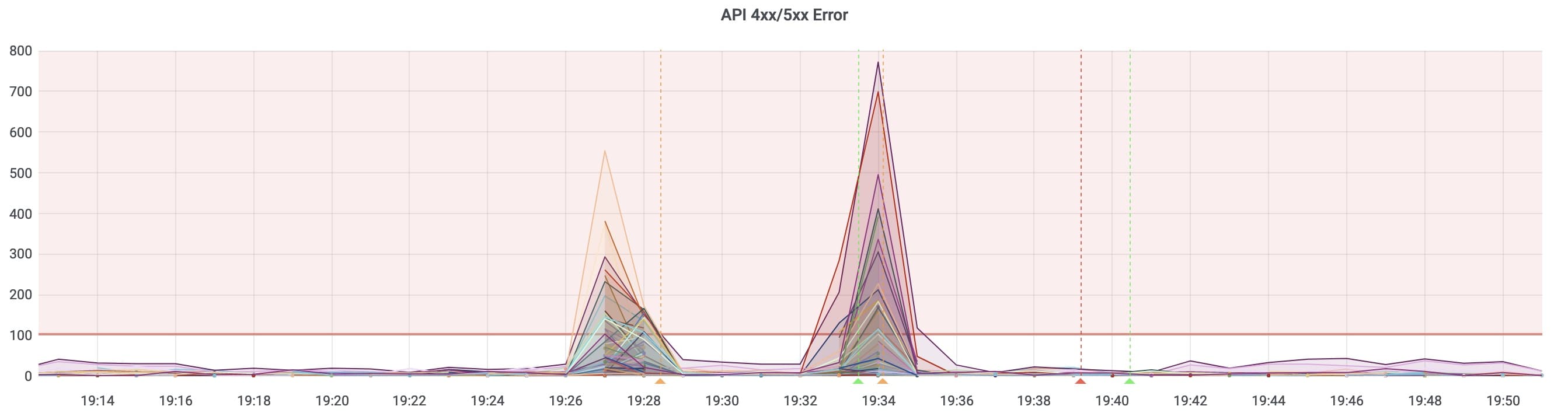
db0:keys=15455371,expires=3032117,avg_ttl=0脚本执行 4 小时后,19:30 Redis 不太稳定,业务使用 Redis 的接口出现报错,随后恢复。
晚上 20:00,TTL Key 变多
# Keyspace
db0:keys=15923132,expires=6870864,avg_ttl=0几天后再次执行 info 命令,Key 总量变少,TTL Key 恢复正常水平
# Keyspace
db0:keys=11828554,expires=2976563,avg_ttl=0内存上涨现象猜想
带有 TTL 的 KEY 比没有失效时间的 KEY 更占用内存?
不会绝对相同。设置 TTL 后,Redis 会在 expires 字典中额外记录过期时间(常见实现里大致是一个指针再加过期时间相关字段,量级约十几字节,具体随版本与编码而异);未设置过期时间的 KEY 不会占用这份 expires 条目。因此「每个 KEY 固定多占 13 字节」的说法过于简化,更准确的说法是:有 TTL 时会多一份过期元数据开销。
长时间不使用且没有 TTL 失效时间的 KEY 会从内存中移除?
猜想是不是跑脚本使原本在磁盘中的数据被加载到内存中,导致内存占用率上升。
Redis 淘汰数据分为两种,TTL 定期淘汰和 LRU 惰性淘汰,惰性淘汰机制是基于内存使用情况的,当 Redis 内存使用量接近设定的最大内存限制时,Redis 并不会立即对 KEY 进行淘汰,而是等到有新的写入操作时,再根据淘汰策略对一些 KEY 进行淘汰。这种方式可以减少 Redis 的 CPU 使用量和内存碎片。
进而了解到策略通过 maxmemory-policy 配置,它有几种可选值:
noeviction:当内存达到上限时,Redis 将不再接受写入操作,所有写入操作都将返回错误。
allkeys-lru:当内存达到上限时,Redis 将对所有 KEY 执行 LRU 算法,删除最近最少使用的 KEY,以释放内存空间。
allkeys-lfu:当内存达到上限时,Redis 将对所有 KEY 执行 LFU 算法,删除访问频率最低的 KEY,以释放内存空间。
allkeys-random:当内存达到上限时,Redis 将随机删除一些 KEY,以释放内存空间。
volatile-lru:当内存达到上限时,Redis 将只对设置了过期时间的 KEY 执行 LRU 算法,删除最近最少使用的 KEY,以释放内存空间。
volatile-lfu:当内存达到上限时,Redis 将只对设置了过期时间的 KEY 执行 LFU 算法,删除访问频率最低的 KEY,以释放内存空间。
volatile-random:当内存达到上限时,Redis 将随机删除一些设置了过期时间的 KEY,以释放内存空间。
volatile-ttl:当内存达到上限时,Redis 将删除那些设置了过期时间,且过期时间距离现在最近的 KEY,以释放内存空间。
在 AWS Redis 参数组中查看,其配置为 "volatile-lru"

内存上限值通过 maxmemory 参数控制,其值为:14037181030 约等于 13.03 GB,跟实例提供的容量一致。
从监控看到可用内存还有 12 GB,远未达到 Redis 自动清理的条件,不会触发淘汰机制,这些 KEY 一直存在于内存中,所以这个猜测也是不对的。
内存碎片化率上升导致可用内存减少?
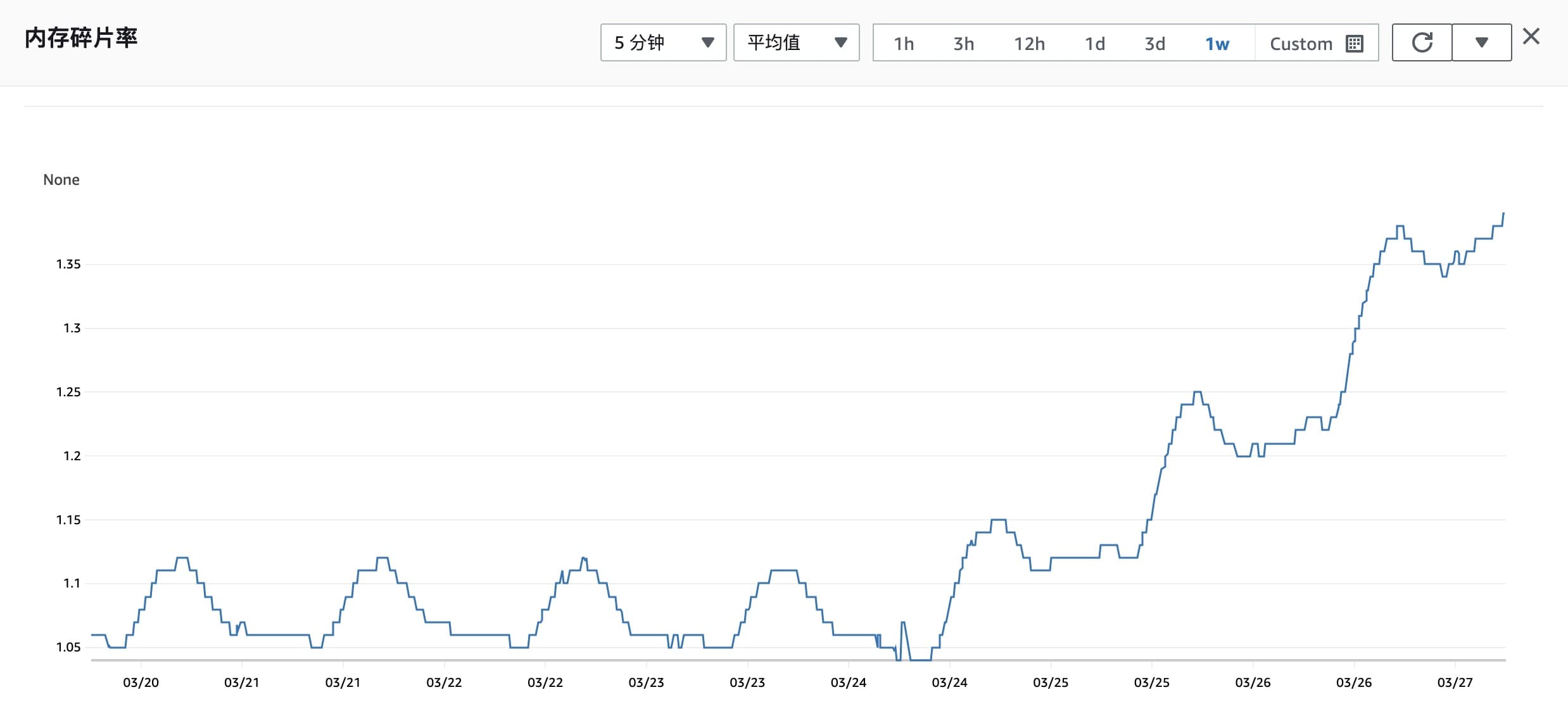
mem_fragmentation_ratio(内存碎片化率)= used_memory_rss (操作系统实际分配给 Redis 的物理内存空间大小) / used_memory (Redis 内存分配器为了存储数据实际申请使用的内存空间大小)
图中可以看到 25、26 号的碎片率上升比较明显(因为 TTL KEY 失效后,used_memory 变小),而在 24 日 15:30 到 20:00 内存碎片化同期大概上涨了 0.04%,AWS 的可用内存指的是 used_memory,所以大概率是因为 used_memory 变小导致的。
可见内存碎片化率上升是因为 Redis 扩容缩容,TTL 失效和删除 KEY 导致的,是 used_memory 变小而 used_memory_rss 不变导致的结果,并不是导致内存上涨的原因。(Redis 并不会立即将内存释放给操作系统)
当使用 volatile-lru 策略时,未设置 TTL 失效时间的 KEY 会存储在 LRU 链表中吗?
在我整理资料时,我突然想到了问 ChatGPT 如上的问题,它给我的答案是肯定的。
当使用 volatile-lru 策略时,未设置 TTL 失效时间的 KEY 不会存储在 LRU 链表中,因为 volatile-lru 策略只会管理具有 TTL 失效时间的键值对,对于未设置 TTL 失效时间的键值对,它们不属于 volatile-lru 策略管理范畴。
另外LRU 链表(LRU list)中的数据每个 Key 大概占用 32 字节左右的空间。
根据对统计图粗略的量化,15:30 到 20:00 新增 Expire KEY 380 万个,KEY 从永久有效设置为 TTL,也就增加 LRU 链表的长度,按 32 字节算,LRU 链表多占用了 116 MB 的空间。
内存上涨现象部分结论
- 15:30 到 20:00 可用内存减少约 280M
- 15:30 到 20:00 新增 Expire KEY约: 380 万
- 15:30 到 20:00 总 KEY 新增约: 46 万
排查后,LRU 链表空间占用变多是 Redis 内存占用上涨的部分原因。至于另外的内存占用,可能因为观测误差,也可能是因为对 Redis 机制了解不够,现场各项数据丢失,不好再进一步定位。
接口报错原因分析
之前认为接口报错是 Redis 不稳定引发的。
但其实内存上涨很小,Redis CPU 消耗也没有波动,于是注意到 Redis 不响应接口很可能是被主进程阻塞住了,于是重新看 Python 脚本的逻辑。
import redis
import time
# 只读 Redis 实例的连接配置
RO_HOST = 'ro_host'
RO_PORT = 6379
RO_DB = 0
RO_PASS = ''
# 可写 Redis 实例的连接配置
RW_HOST = 'rw_host'
RW_PORT = 6379
RW_DB = 0
RW_PASS = ''
# 模糊查询字符串
QUERY_STR = 'some_string'
# 扫描游标初始值
cursor = 0
ro_r = redis.Redis(host=RO_HOST, port=RO_PORT, db=RO_DB, password=RO_PASS)
rw_r = redis.Redis(host=RW_HOST, port=RW_PORT, db=RW_DB, password=RW_PASS)
# 扫描循环
loop = 0
while True:
# 扫描当前游标位置开始的键值
cursor, keys = ro_r.scan(cursor=cursor, match=f'*{QUERY_STR}*', count=100)
# 遍历符合条件的键值(SCAN 可能返回空列表,但 cursor 未回 0 时仍需继续)
for i, key in enumerate(keys):
# 动态设置 TTL
cnt = 100*loop + i
delay = 10000 + cnt
if delay > 259200: # 3 天内都失效
loop = 0
rw_r.expire(name=key, time=delay)
print(f"{cnt}, key {key}, expire delay {delay}")
# 防止过多的扫描操作对性能造成影响
time.sleep(0.3)
loop += 1
# cursor 回到 0 表示本轮 SCAN 完成
if cursor == 0:
break因为 SCAN 是搜索的从库,问题大概率出在 expire 上,循环 100 次无间隔快速执行 expire 无间隔,而 19:30 又是服务访问量上涨期间,Redis 主进程压力变大,就会增加阻塞主进程的概率。
那么,脚本可以使用 pipeline 批量执行,减少 Redis 主进程处理命令的次数,从而减轻 Redis 主进程的负载,另外,脚本也应在服务访问量低的时间段运行。
pipe = r.pipeline()
for key in ['key1', 'key2', 'key3']:
pipe.expire(key, 3600)
pipe.execute()后续删除
考虑到线上代码已经修复,库中没有 TTL 的 KEY 可以直接删除掉。
从库查询出所有没有 TTL 的 KEY
import redis
# 创建 Redis 客户端
r = redis.Redis(host='your-redis-host', port=6379, db=0)
# 定义扫描数量,连接业务库应降低其数值
COUNT = 1000
cursor = 0
while True:
cursor, keys = r.scan(cursor=cursor, count=COUNT)
# 遍历所有键并检查是否有 TTL
for key in keys:
ttl = r.ttl(key)
if ttl == -1:
print(key)
if cursor == 0:
break我通过重定向将内容输出到文件
python3 query.py >> no_ttl_keys.txt查询出的 KEY 很多,通过 Bash 脚本过滤包含指定字符串的记录
while read -r line
do
if [[ "$line" == *"some_string"* ]]; then
echo "$line" >> no_ttl_keys_filter.txt
fi
done < no_ttl_keys.txt因为数据过多,将数据十等分
$ split -n l/10 --additional-suffix=.txt --numeric-suffixes=1 no_ttl_keys_filter.txt no_ttl_keys_filter_而后通过 python 脚本删除
import redis
import time
import os
# Redis 连接参数
redis_host = "your-redis-host"
redis_port = 6379
redis_password = ""
# 待删除 KEY 文件名
key_file = "no_ttl_keys_filter_01.txt"
# 连接 Redis
r = redis.Redis(host=redis_host, port=redis_port, password=redis_password)
# 打开待删除 KEY 文件
with open(key_file, "r") as f:
# 逐行读取 KEY 并批量删除
pipeline = r.pipeline()
for i, key in enumerate(f):
key = key[2:].strip("'\"\n") # 之前存储的数据包裹 b'{key_name}'
pipeline.delete(key.strip())
if i % 50 == 49: # 每次批量删除 50 个
result = pipeline.execute()
time.sleep(0.3)
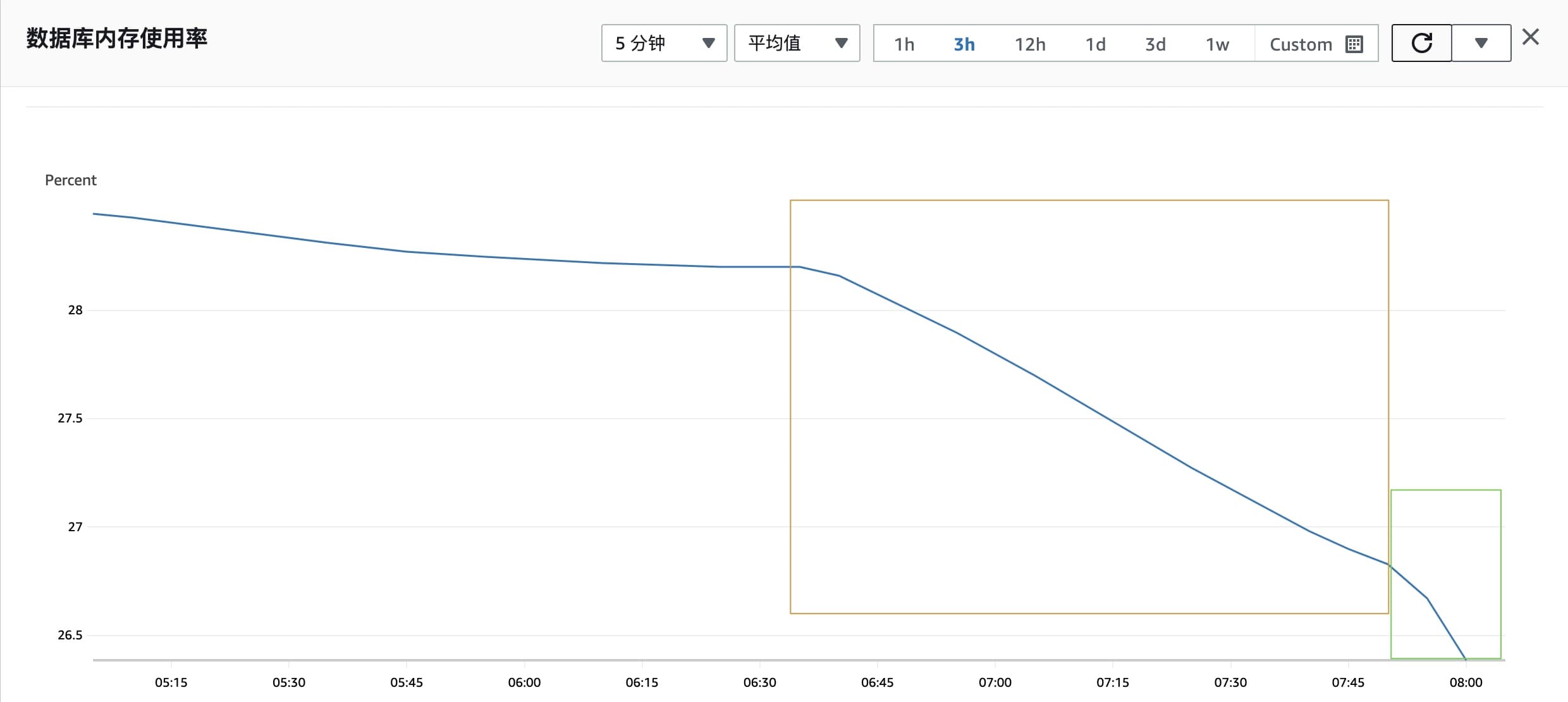
print(time.time(), i, result)批量删除执行后,监控可以看到内存使用率开始降低。
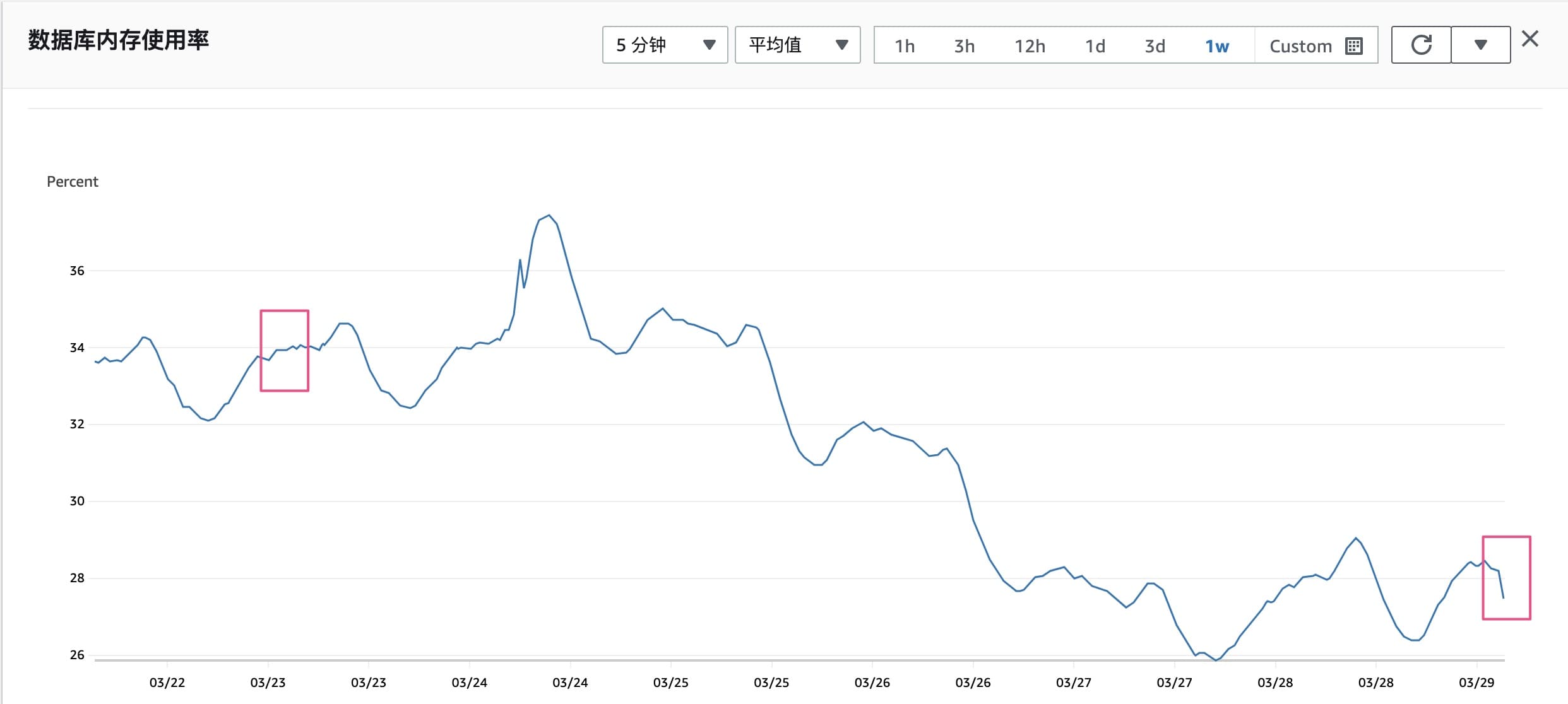
在线上稳定的前提下,可适当增加批处理的 KEY 数量,时间间隔也可适度降低为 0.1,以加快处理速度。
结论
- 内存上涨原因(部分):为不过期的 KEY 设置 TTL 增加了 LRU 链表的空间占用。
- 接口报错原因:Python 脚本在运行时一次获取到 100 个 KEY,循环执行 expire 命令设置失效时间,这个循环会对 Redis 的主进程造成压力,时业务访问量上升区间时,脚本增加了 Redis 主进程阻塞概率,导致接口报错。
解决方案
- 使用 Pipeline 批量设置多个 Key 的 TTL(或批量删除),减少 Redis 主进程处理命令的次数,从而减轻 Redis 主进程的负载。
- 在业务低峰时间段执行脚本。
遗留问题
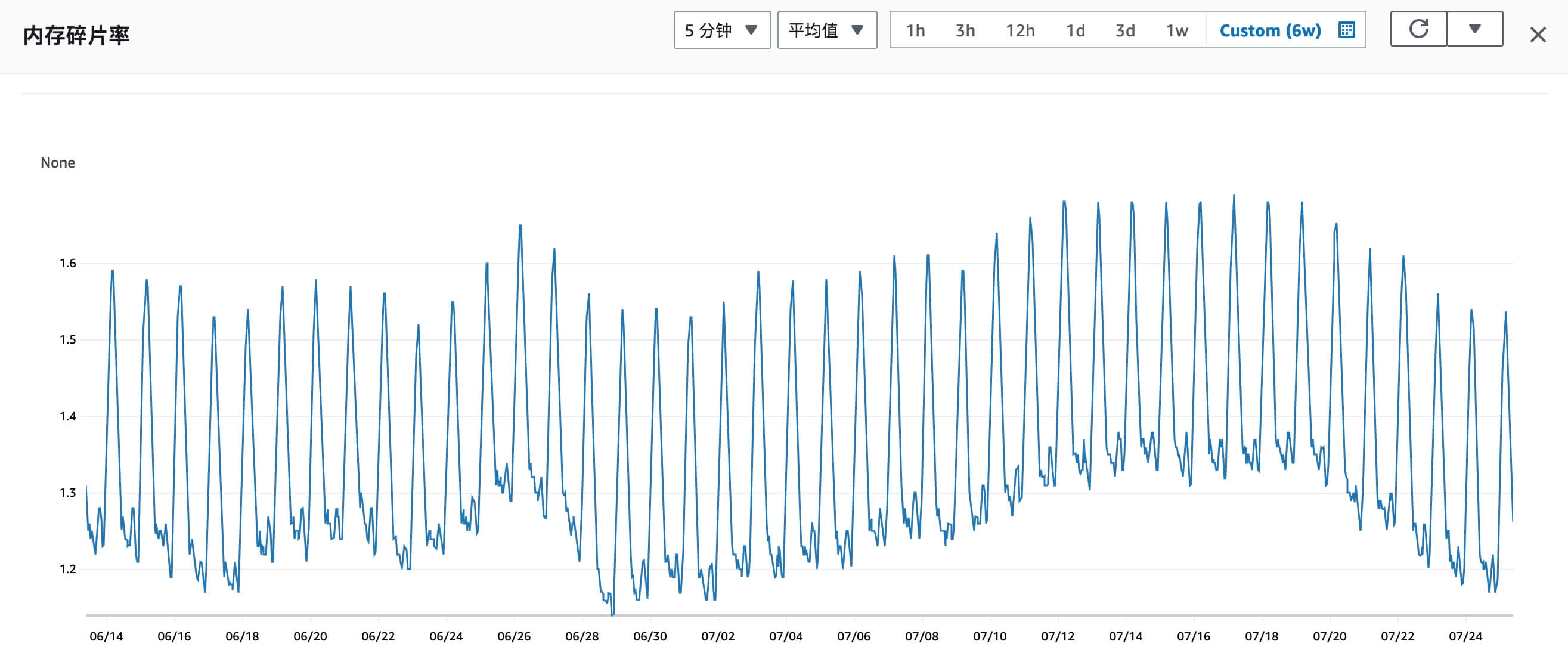
如何降低 Redis 磁盘碎片率?这个后文记录,不在这里补充了。
2023-04-20 补充
磁盘碎片率在使用过程中有下降趋势,预计可自行恢复
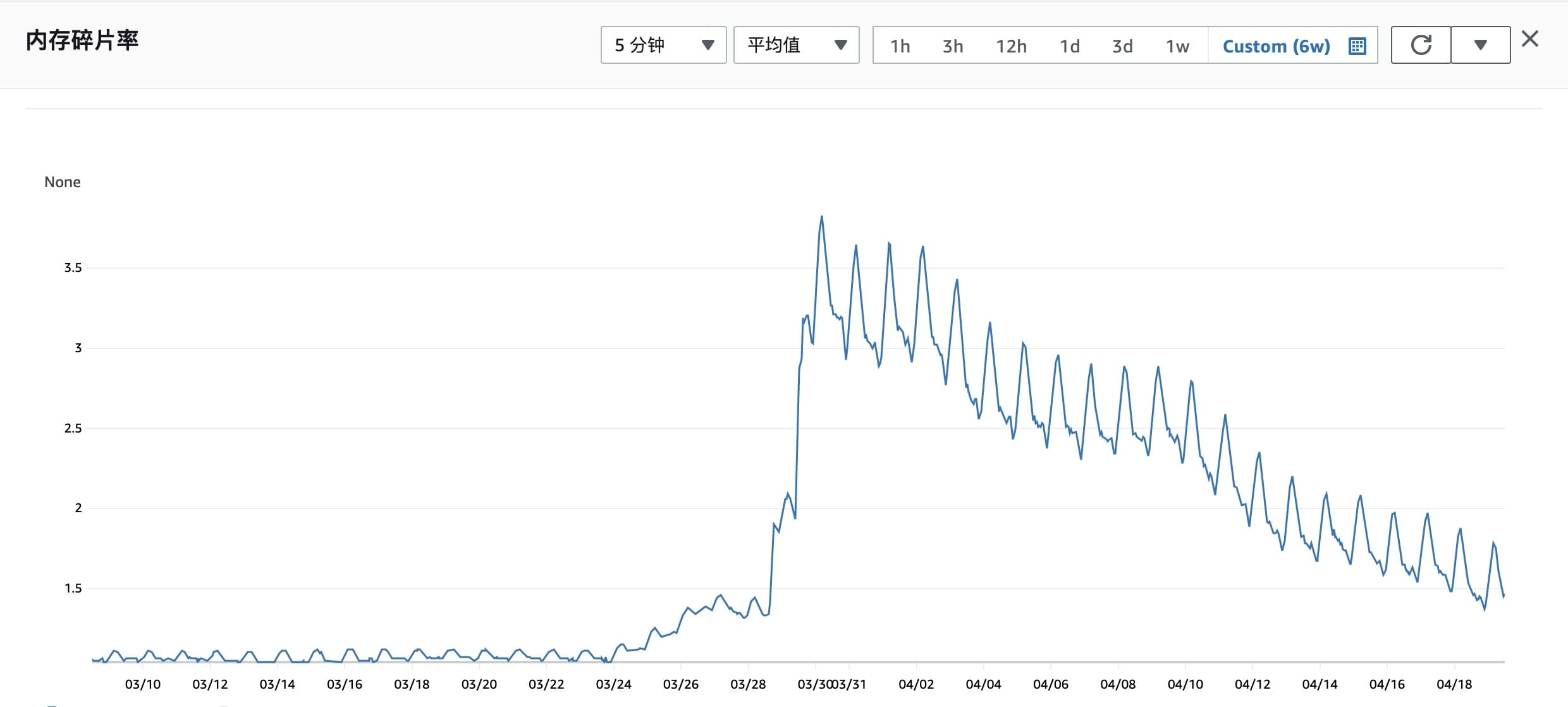
2023-07-26 补充
经过几个月的观看,看起来降到 1.2 碎片率就降不动了,同时碎片率浮动较大,在 1.2 到 1.6 间波动,无法自行恢复回到之前的状态。