异常现象
前两天维护线上服务,注意到 Grafana 面板上两台 EC2 的 CPU 消耗差异巨大,如下图
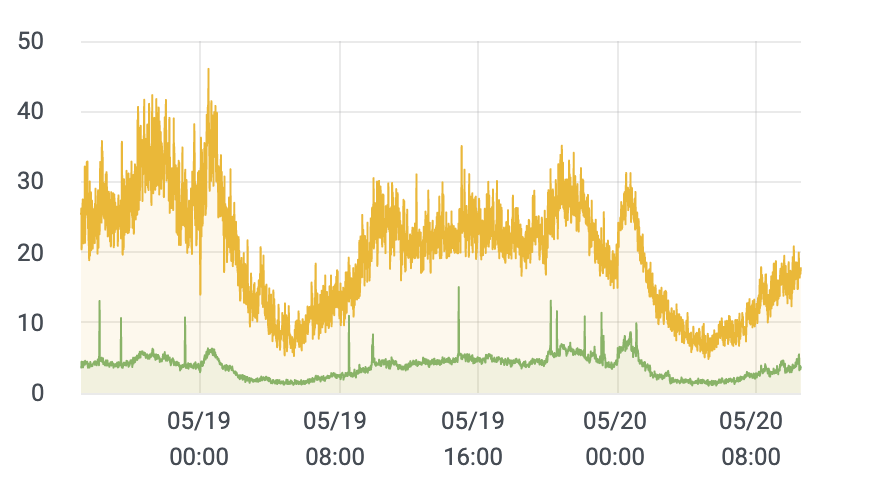
前一阵儿看另外的服务,我以为 Vector 本身就很消耗资源,还想着找找看有没有 Rust 实现的类似服务替换下,结果发现 Vector 就是 Rust 写的,那遇到性能问题大概率是使用方式的问题。
初步定位
首先想到负载是不是不均衡,但看请求量,两个机器的请求量是相同的。
- 两台负载均衡没有问题
- 核对两台机器 EC2 机型一样
到机器上用 ctop 查看,很快发现是 vector 服务消耗了大量 CPU,导致整体 CPU 偏高。
- 核对两台机器 Vector 配置是一致的
- 并且两台机器 Vector Status OK,都在正常工作
完全都相同的资源和配置,CPU 消耗差距这么大。
基础服务是用镜像启动的,想要进一步定位问题,需要进一步了解 Vector
了解 Vector
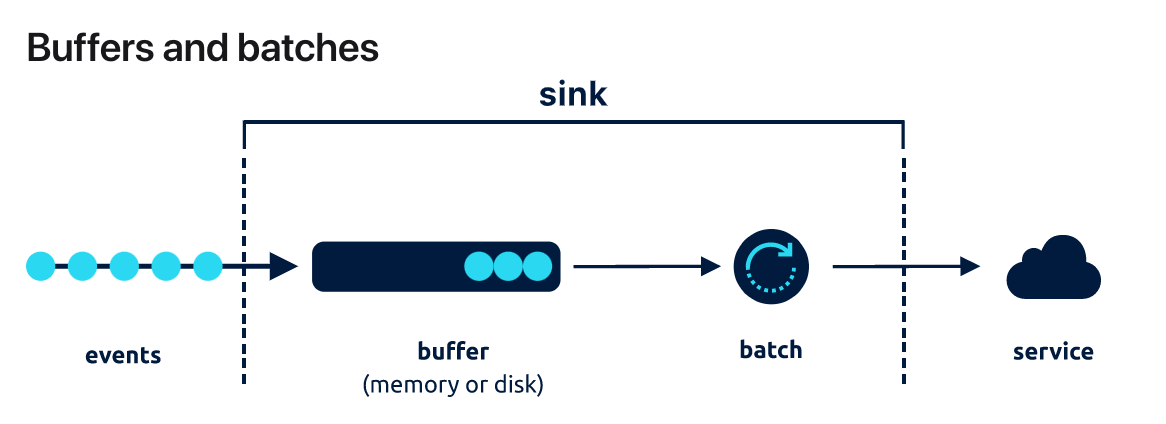
翻看 Vector 文档,了解到日志会先到 Buffer,再到 Batch,满足一定条件条件后,Batch 会批处理数据推送到远端。
当前服务器上的配置 (/etc/vector/vector.toml)
# Batch
batch.max_size = 10485760 # 10M
batch.timeout_secs = 60
# Buffer
buffer.type = "disk"
buffer.max_size = 1073741824 # 1G
buffer.when_full = "block"看着没什么问题,我尝试搜索 “Vector high CPU”,看到一个 Issue 中的评论截图跟我的现象类似 Github:#4582#issuecomment-711112967
评论者没有最终找到问题的原因,不过补充了“绕过问题”的方案,将 Buffer 放在 memory 中。

猜想与测试
调整配置如下
# Batch
batch.max_events = 100
batch.timeout_secs = 60
# Buffer
buffer.type = "memory"
buffer.max_events = 1000
buffer.when_full = "drop_newest"重启后,CPU 消耗大幅下降
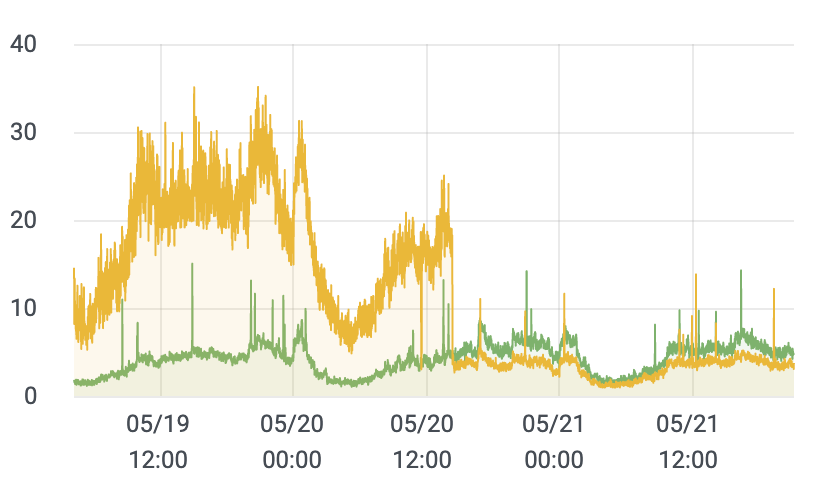
那么大概能得出两个结论
- 那台高 CPU 消耗的机器与 Vector 磁盘缓存或批处理相关
- 使用内存缓存比磁盘缓存的CPU资源消耗更小
根据磁盘缓存相关的线索,进一步查看 s3 sink 的数据目录,通过比较可以发现两台机器的目录数据有较大差异,不过从存储的数据来看,并没有发现什么问题,翻看数据文件看,有些已经创建许久,可能已不再使用。

找了有类似现象的机器,将数据目录删除,然后重启看看现象。
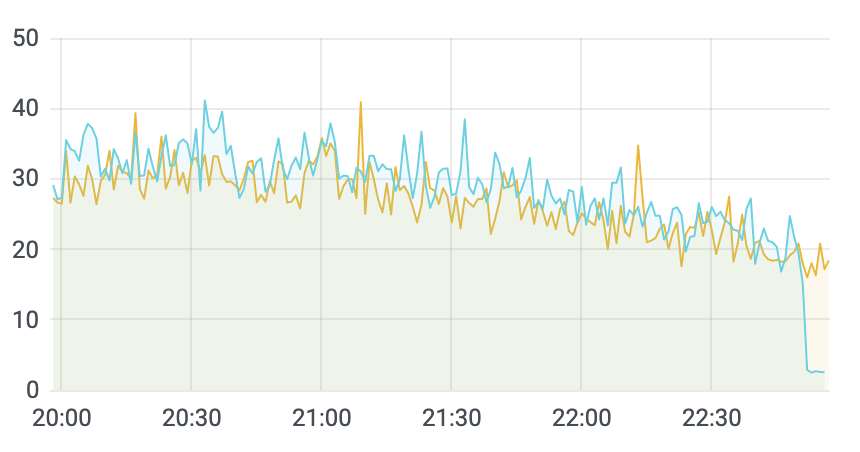
删除目录重启后 CPU 的消耗有显著的下降,之前看到的“过期”数据目录可能是导致 Vector 高 CPU 消耗的原因。
但目前没找到更为详尽的文档和线索来支持这一猜想,可能需要等待着台删除数据目录的机器再次变为高 CPU 消耗的时候,再寻找线索。
补充内容
在了解 Vector 过程中,有个 Issue 有助于了解 Buffer 和 Batch 协作。
Prevent batching/buffering deadlock #355
里面问了当 Buffer 的最大长度小于 Batch 批处理的触发大小时是什么样的行为?
To test, I hooked up a generator source to a http sink, and fed it to a dummy HTTP server that just gave 200 responses to every request. I set up a 1,000 byte disk buffer and a 10,000 byte batch buffer with a long timeout. In that configuration, Vector sends serial requests of just over 1,000 bytes. If the disk buffer size is larger than the batch buffer, Vector sends parallel requests (up to request.in_flight_limit) just under 10,000 bytes long.
简单说就是经过测试,如果小于 Batch 触发 Size,那么当超过 Buffer 时会串行的发送数据,反过来则会并行消费 Buffer 内的数据。
这里还有个 Issue 列了优化方向,计划 Vector 应该有更加智能化的 Buffer 和 Batch 默认行为,不应过于依赖用户对其的配置参数。目前 Issus 还是 Open 状态,可能没有进展。
Improve buffer defaults (automatic sizing + overflowing) #10280
推荐方式
在现有对 Vector 了解的基础上,如果能够接受日志数据在 Buffer 满后会丢失,则使用 Memory 来做 Buffer 是性能最好的选择。
# Batch
batch.max_events = 100
batch.timeout_secs = 30
# Buffer
buffer.type = "memory"
buffer.max_events = 10000
buffer.when_full = "drop_newest"否则,基于磁盘来存储重要数据,做好监控。
遗留问题
通过使用 Memory 规避掉了问题,但是目前还有些不完美的地方
- 磁盘缓存导致高 CPU 的原因是什么,Vector BUG 或者?
- 什么情况下,Batch 处理速度会跟不上数据产生速度,造成 Buffer 增长
- 使用内存做 Buffer 后,能否对 Buffer 长度进行监控
解决问题的方式不完美,后续有结论再补充。