Toast 是什么?
PostgreSQL 中的 Tuple(行数据)是存储在 Page 中的,而 Page 的大小默认为 8KB,PostgreSQL 不允许 Tuple 跨页存储,所以当一行数据的某个列数据过大时,就会将它存储在单独的表中(称为 Toast 表),比如 Text 类型的数据超过了单页的大小,那么 Toast 会将它压缩,切分,并且存储在另外的位置,这种技术就是称为 Toast。
当待插入元组的大小大于约为 2KB(即页的1/4)时候,会自动启动 Toast 技术来存储该元组。
元组数据存储前会压缩,如果压缩后小于限制,也不会存入 Toast,当压缩后也不满足要求时,会进行切分存入对应的 Toast 表。
准备测试环境
macOS 通过 brew 安装 PostgreSQL
$ brew update
$ brew tap homebrew/core
$ brew install postgresql
$ brew services start postgresql创建用户
CREATE ROLE dong WITH LOGIN PASSWORD 'password123';
ALTER ROLE dong CREATEDB;To start postgresql@14 now and restart at login: brew services start postgresql@14 Or, if you don't want/need a background service you can just run: /opt/homebrew/opt/postgresql@14/bin/postgres -D /opt/homebrew/var/postgresql@14
创建表
CREATE TABLE public.t
(
A INTEGER,
B INTEGER,
C VARCHAR
);不是所有的表都有对应的 Toast 表,只有当表中存在变长的数据列,才会有一个对应的 toast 表,专门存储过大的数据。
添加测试数据
BEGIN;
INSERT INTO t (A, B, C) VALUES (1, 1, 'eW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZckeW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZck');
COMMIT;此处生成的数据方式不对,是使用 “eW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZck” 复制粘贴出来的,之前验证的时候发现在 Toast 表找不到数据。
后来看到有文章提及到压缩后判断,才意识到这个问题,测试的时候建议选择一个 100KB 左右的图片,用 Base64 编码后的数据当作变长数据进行测试。
查询对应的 Toast 表及索引表
查询表对应的 Toast 表及 OID
-- 对应的 Toast 表
SELECT reltoastrelid::regclass FROM pg_class WHERE relname = 't'; -- pg_toast.pg_toast_16386
SELECT relname FROM pg_class WHERE oid = (SELECT reltoastrelid FROM pg_class WHERE relname='t'); -- pg_toast_16386
-- 表及 Toast 表的 OID
SELECT oid FROM pg_class WHERE relname = 't'; -- 16386
SELECT oid FROM pg_class WHERE relname = 'pg_toast_16386'; -- 16389查询 Toast 表及其索引
SELECT
relname,
relpages,
oid
FROM
pg_class,
( SELECT reltoastrelid FROM pg_class WHERE relname = 't' ) AS ss
WHERE
oid = ss.reltoastrelid
OR oid = ( SELECT indexrelid FROM pg_index WHERE indrelid = ss.reltoastrelid )输出
pg_toast_16386 0 16389
pg_toast_16386_index 1 16390查询表原始数据
SELECT * FROM get_raw_page('t', 0);如果报错则需要添加扩展
ERROR: function get_raw_page(unknown, integer) does not exist
LINE 1: SELECT * FROM get_raw_page('t', 0)
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
, Time: 0.002000s添加扩展
-- 查看是否有 pageinspect 扩展
SELECT * FROM pg_extension;
-- 安装 pg_prewarm 扩展,否则无法使用 get_raw_page() 函数
create EXTENSION pageinspect; 如果提示权限不足,则赋予权限
-- 已存在用户
ALTER ROLE dong WITH SUPERUSER;
-- 新建用户
CREATE ROLE super WITH SUPERUSER;之后再次执行 SQL
SELECT * FROM get_raw_page('t', 0);如果使用 Navicat,默认显示 “(BLOB) 8KB”,可以点击查询框上的编辑器,选择 16 进制,再点击一下 BLOB 列即可。

可以看到右侧的数据,内容即为 “eW6vtvRwaDq9nRveYLPNQ2jePsZWDmmm7t28BP8QRQMLFT5S3KVwGjsaHPxLDxjMkaR9GHn8mNXCY6ZKDkVRg7Fb2QivMeJrQJgDypLiWVKvibv8nXhy8f4XbwrvaZck”,下方有不断重复的 . ... 应该就是 PostgreSQL 数据压缩后表示重复的标识了,也是我之前验证时发现数据没有写到 Toast 的原因。
等到插入图像 Base64 数据后,因为压缩后也会超过大小限制,会被写入到 Toast 表。
查看 Toast 表内容及原始数据
SELECT ctid, * FROM pg_toast.pg_toast_16386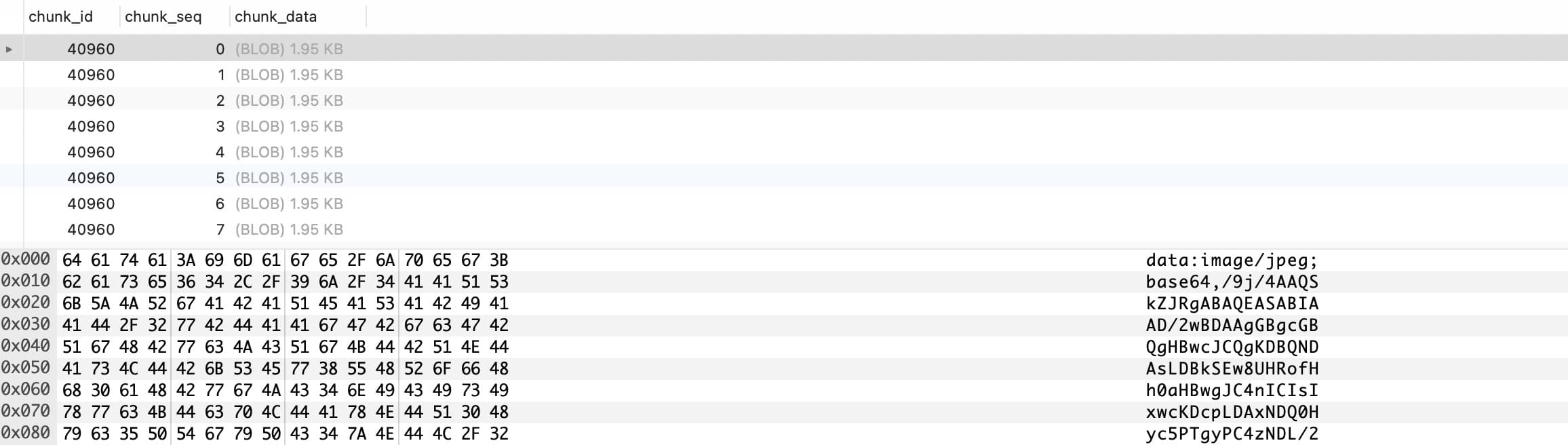
观察上图,有几个字段,chunk_id 表示这是一个数据的分片记录,chunk_seq 是序号,chunk_data 是数据,第一个切片中的数据在右下角,可以看到我们存储的数据以 “data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIA” 起始,被切割存储的。
切片的策略和选择
上面展示了 PostgreSQL 对变长数据的默认切片策略,其实它还提供了别的策略。总共支持四种,如下所示:
- PLAIN,数据不能被压缩,也不能存储到 Toast 表
- EXTENDED,默认策略,可以被压缩,也可以存储到 Toast 表
- EXTERNAL,不能被压缩,但可以存储到 Toast 表
- MAIN,可以被压缩,也可以存储到 toast 表,只不过它的优先级比 EXTENDED 低
技术比较 PostgreSQL 并没有使用跨页存储的方案,而是将大型数据单独放到其余地方存储。这样在条件过滤时,会比较好,因为它不需要读取这些大的数据,而且只有当该列被选中时,才会在返回数据时去读取。这种场景下,减少了磁盘 IO 的读取,提升了性能。
同样它也有对应的缺点,那就是写入大型的数据时,会比较慢。因为它需要切片,然后插入到 Toast 表中,还要更新 Toast 表的索引。如果采用跨页存储,那么还可以利用磁盘顺序写的高性能。在读取整行数据时候,还需要先去寻找 Toast 表的索引,然后再去读取 toast 表的数据,相比较跨页存储,仍然无法使用磁盘顺序读的高性能。
引用自:https://zhmin.github.io/posts/postgresql-toast/
在存储大文本时,VARCHAR 在不指定 n 时和 TEXT 没有区别,性能是一样的。当存储的内容是图像、音视频、文档等二进制数据时推荐使用 bytea 数据类型。
当 bytea 类型的数据超过阈值被存储到 Toast 时,不会被解析,会按照原始的二进制数据进行存储。
测试存储二进制文件
CREATE TABLE public.t2
(
A BYTEA
);示例 pyhton 代码
import psycopg2
# 连接数据库
conn = psycopg2.connect("dbname=tmp01 user=dong password=password123")
# 获取Cursor对象
cur = conn.cursor()
# 打开图片文件读取内容
with open('1.jpg', 'rb') as f:
binary_data = f.read()
# 插入数据语句
insert_query = "INSERT INTO t2(a) VALUES(%s)"
# 执行插入,并传入bytes数据
cur.execute(insert_query, (binary_data,))
# 提交事务
conn.commit()
# 关闭连接
cur.close()
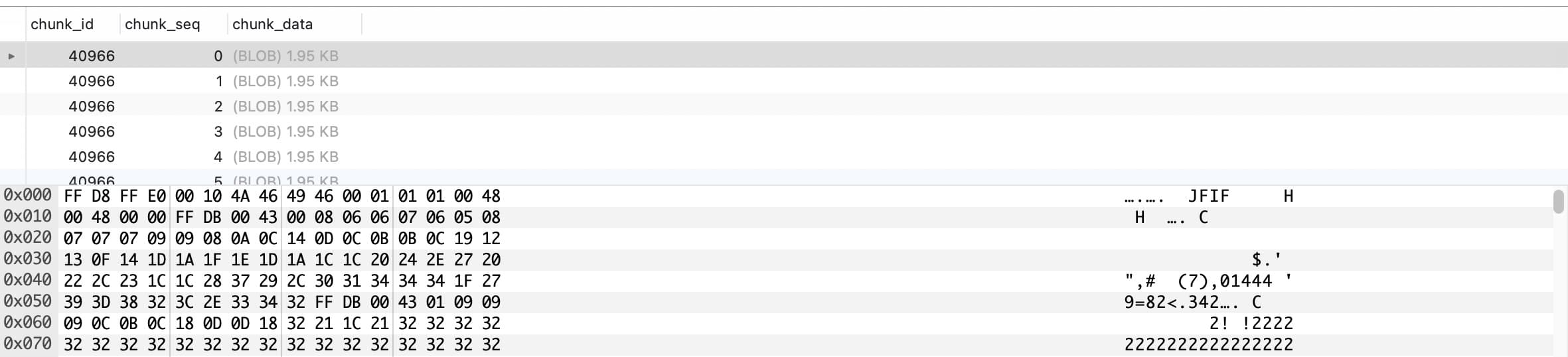
conn.close()插入后按上面的方式查找其 Toast 表,查看数据,可见也被切割为 1.95 KB 的记录进行存储,这是因为 Toast 和主表的一样,每条记录都有 2KB 大小的限制。
调整移动字段到 Toast 表的阈值
PostgreSQL 默认当字段大于 2KB 时会将其存储到 Toast 表,如果需要设置这个值,可以使用以下 SQL,取值范围是 128 ~ 8160,8160 是 PostgreSQL 行的最大值。
ALTER TABLE t2 SET (toast_tuple_target=128);一般无需修改,调小这一数值的部分可能原因如下:
释放主表空间: 主表空间是宝贵的,小字段值占用的空间通过 toast 可以释放出来。 查询性能提升: 大字段值不在主表中,主表更小更紧凑,单行扫描和查询性能有提升。 增量维护: 主表每一行修改都需要全量更新,而 toast 表支持非整行更新,更高效。
除了 TOAST_TUPLE_TARGET,我们也应知晓 TOAST_TUPLE_THRESHOLD,它们默认都是 2KB,当字段大于 TOAST_TUPLE_THRESHOLD 时将尝试压缩,如果压缩后小于 TOAST_TUPLE_TARGET 则会被存储在主表,不会被放置到 Toast 表
查询主表及 Toast 表的空间占用
SELECT
pg_size_pretty(pg_relation_size(oid)) table_size,
pg_size_pretty(pg_relation_size(reltoastrelid)) toast_size
FROM pg_class
WHERE relname = 't';
Toast 基础知识暂时先了解到这里,有时间针对使用场景继续深入研究。