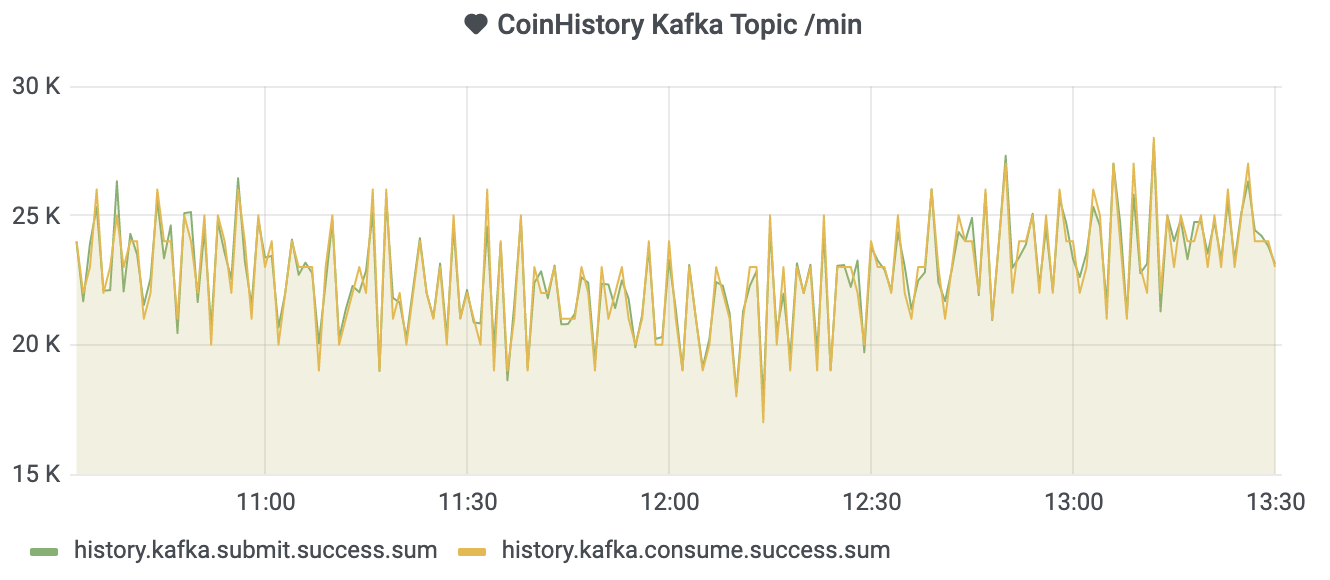
线上历史记录产生速度较快,逐条插入数据库导致数据库负载较高,一个可行的方案是将历史记录写入队列,而后批量插入数据,这个场景非常适合 Kafka —— 吞吐量高,能够对流量进行削峰,数据存储在磁盘,即使消费者停止也能将消息存留一段时间不至于丢失。
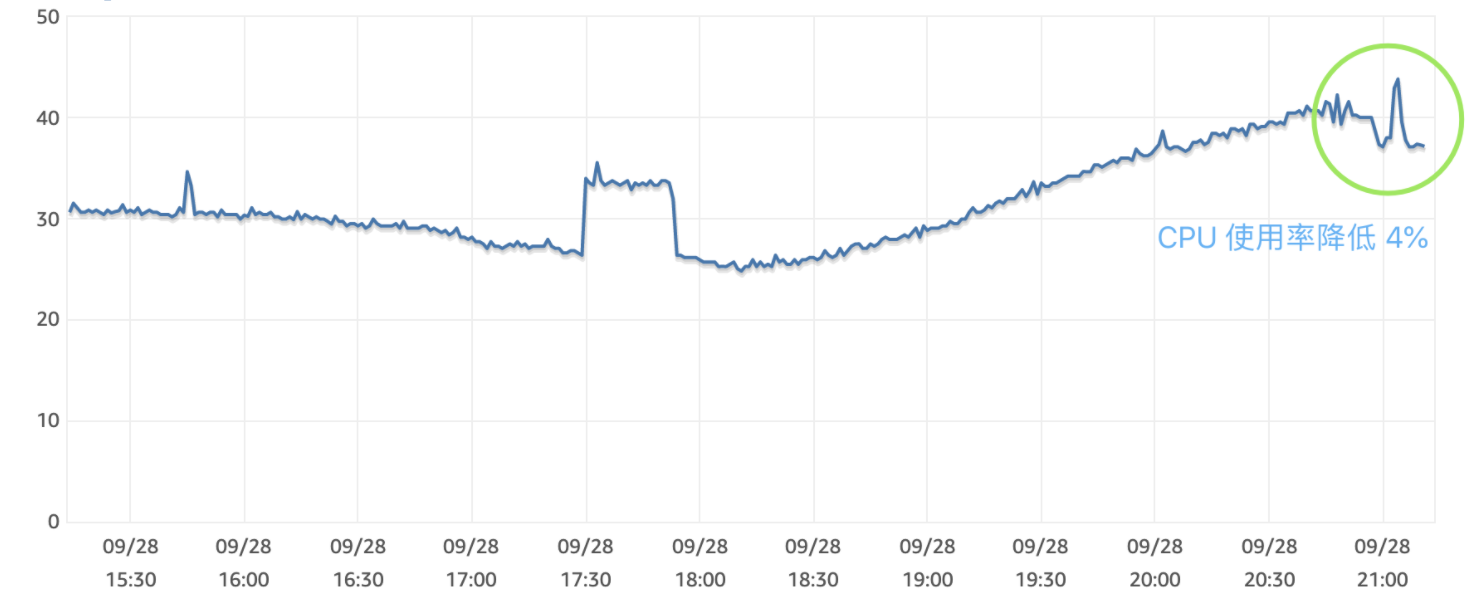
最终决定基于 Kafka 进行优化,优化为批量写入后,高峰段 CPU 负载下降 4 ~ 5%
Kafka 服务已由同事单机部署,调研及线上接入过程中,遇到一些之前没考虑到的事项,本文加以记录
调整配置
# 监听配置
listeners=PRIVATE://172.27.36.233:9092,PUBLIC://172.27.36.233:9094
advertised.listeners=PRIVATE://172.27.36.233:9092,PUBLIC://86.123.77.23:9094
listener.security.protocol.map=PRIVATE:PLAINTEXT,PUBLIC:PLAINTEXT
inter.broker.listener.name=PRIVATE
# 自动创建主题
auto.create.topics.enable=true
# 数据存储目录
log.dirs=/var/kafka-data/kafka-log
# 保留时间(默认一周)
log.retention.hours=168
# 一个分区大于多少被删除,默认被注释中,取消注释达默认1GB后删除,此处改为30GB,作为保险值
log.retention.bytes=32212254720
# 当日志写满一个文件切换为另一个文件,文件大小默认为1GB
log.segment.bytes=1073741824
# 删除主题时从磁盘完全移除数据,False时为标记删除
delete.topic.enable=true补充说明:
- 配置中 172.27.36.233 为内网地址,86.123.77.23 为外网访问地址(已修改为非线上IP)
log.retention.hours和log.retention.bytes满足一个就会触发删除,当log.segment.bytes触发切换写入的日志文件后,日志即进入删除规则判定。- 存储上限制(eg. 30GB 是针对于单分区的限制),如果主题有三个分区,那么实际上,总存储数据会有 90GB
Golang Kafka 库
地址:https://github.com/segmentio/kafka-go
默认机制
- 写入速度较慢的时候,Writer 会每秒提交一次数据到 Kafka,不会按调用频率每次调用都提交,这样的好处是可以“攒够”一定数量的消息批量提交,效率更高。
- 写入速度很快的时候,每达到 100 条消息,Writer 会提交一次,保证消息的及时提交。
代码示例
首先获取 Writer,我的策略是一个主题一个 Writer,直接调用 Writer 写入数据。
w := GetWriter(topic)
if err := w.WriteMessages(context.Background(), kafka.Message{Value: message}); err != nil {
statsd.ReportKafkaSubmitError(topic)
log.App().Error("post -> kafka queue error", zap.Error(err))
} else {
statsd.ReportKafkaSubmitSuccess(topic)
log.App().Debug("post -> kafka message success")
}生产者 & 协程池
Ants 协程池库
Github:https://github.com/panjf2000/ants
非阻塞模式
默认使用阻塞模式,当协程不够时,超出的调用会进入阻塞状态,接口等待而后失败,对服务影响较大,使用非阻塞模式,协程耗尽后调用会抛出错误,不影响接口业务流程,仅会导致部分历史丢失,影响较小。
p, err := ants.NewPoolWithFunc(poolCount, func(payload interface{}) {
data := payload.(Payload)
writeMessage(data.Topic, data.Message)
},
ants.WithOptions(ants.Options{
Nonblocking: true, // 非阻塞,
PanicHandler: handlerPanic,
}),
)协程数评估
当前线上历史记录插入速度约为一天 3400 万条记录,约 400 条/s
假设服务具有 500 次/s 写入的能力,当使用 10 个协程时,等待时间过长,经测试后,100 个协程的效果最好
| 协程数量 | 本地 CPU 消耗 | 写入所需时间(秒) |
|---|---|---|
| 10 | 0% | 51.339 |
| 20 | 0% | 26.434 |
| 30 | 0% | 18.441 |
| 50 | 0% | 10.713 |
| 100 | 15~22% | 0.17 ~ 0.6 |
| 200 | 25 % | 0.17 |
评估是美好的,但上线后会发现有报错,在上线后的调整过程中发现:线上 100 协程,会有较多 Invoke 报错,调整到 200 后减少但依然存在,调高到 300 协程后报错消失
批量插入数量评估
将线上数据写入测试数据库可以看到逐条写入数据库时 CPU 使用率上升明显,随着批量写入记录数的增加,CPU 使用率显著下降,同时需要注意的是,不代表批量插入的记录数越多越好,随着批量插入数的提高,有两个新的问题需要注意:主键冲突与低峰段时效性降低
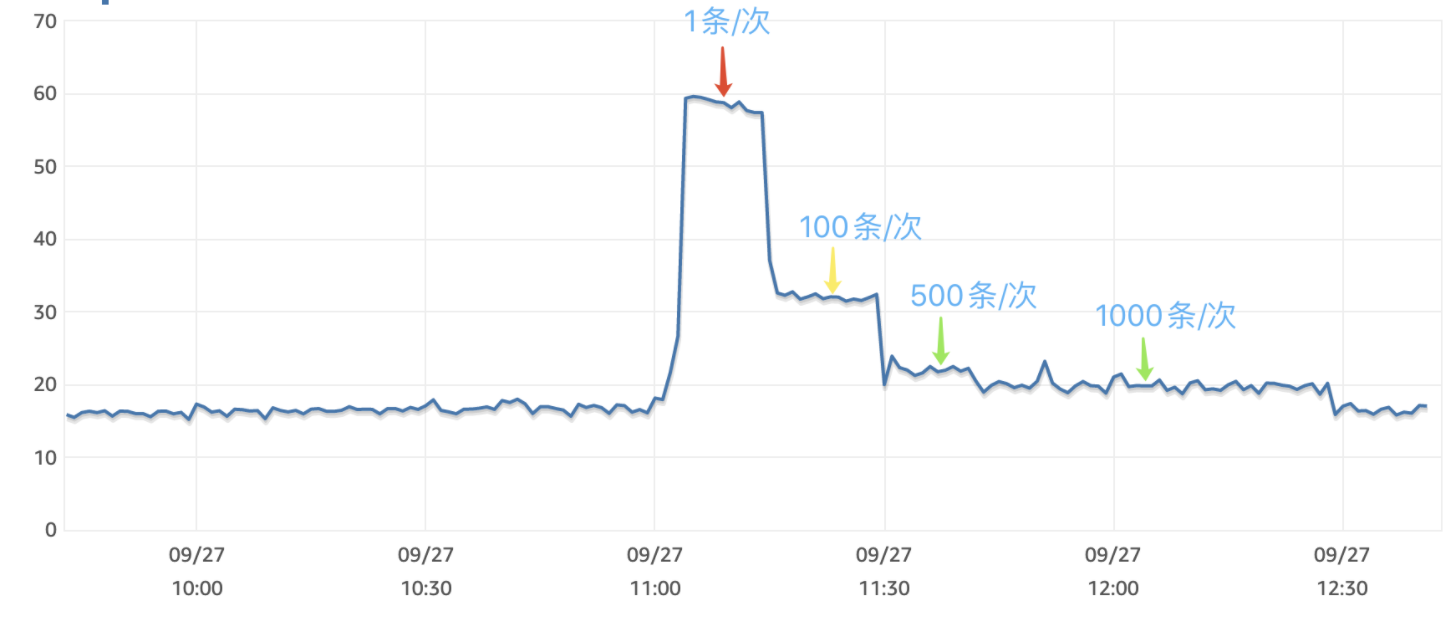
批量插入带来的问题
主键冲突
HistoryID 当前长度 14 位(例:“1632572156jsyo”),批量插入时遇到重复的ID会导致数据插入失败。
history insert db success: 500
history insert db success: 500
history insert db success: 500
history insert db success: 500
history insert db success: 500
[xorm] [error] 2021/09/27 03:31:04.112119 [SQL][0xc000510900] pq: duplicate key value violates unique constraint "history_pkey"
history insert db failed pq: duplicate key value violates unique constraint "history_pkey"
history insert db success: 500
history insert db success: 500
history insert db success: 500
history insert db success: 500
history insert db success: 500这是一个历史遗留问题,线上逐条插入到数据库也会有因为主键冲突导致的失败,采用批量插入 500 条,那么失败一次就会丢失 500 条记录,放大了丢失消息的数量。
最后的解决办法是在业务中,增加主键的长度,秒级别时间戳变为毫秒时间戳,同时随机的4位字符串调整为6位
解决冲突后,尝试每次批量插入 1000 条,没再遇见主键冲突的报错。
低峰段时效性降
权衡了 500、1000、2000 批量写入数量,1000 能同时兼顾性能与时效性。
单一消费者处理能力
[查询消费者信息] kafka-consumer-groups.sh --bootstrap-server 172.30.7.233:9092 --describe --group the-go-consumer
| 时间点 | CURRENT-OFFSET | LOG-END-OFFSET | LAG |
|---|---|---|---|
| 下午 3.18 | 41267459 | 83909703 | 42642244 |
| 下午 3.48 | 41889780 | 84738103 | 42848323 |
CURRENT-OFFSET 为当前消费者偏移(已消费记录数),LOG-END-OFFSET 为当前 Topic 消息消费者可见数量(总消息数量),LAG 为待消费消息数。
由表可知,单一消费者的消费能力有限,随着时间的推移,积压的消息没有被消费,反而积压情况进一步加剧、重,单一消费者消费能力不足是之前没有考虑到的,想要增加消费者数量,需要同时增加分区数。
分区数量评估
同一个消费组内,一个消费者可以消费多个分区,但同一个分区不能被多个消费者消费,即分区数决定了同组消费者个数的上限,同一时刻,一条消息只能被组中的一个消费者实例消费。
根据消费速率,金币历史至少应该有两个分区,具备 250W 条的消费能力,才能避免消息积压。
按平均 400条/s 生成速度估算,2 个消费者每秒能处理 688 条记录,3 个消费者能处理 1033 条,线上在新增同时消费数据,2 个消费者每秒处理 288 条积压记录,3 个消费者处理 633 条积压记录。
(表中数据仅作评估,不用的机器实例、数据库、生产者/消费者,实际数值均不相同)
| 积压时间 | 消息数 | 2 个消费者 | 3 个消费者 |
|---|---|---|---|
| 1 小时 | 144 W | 1.4 小时 | 0.6 小时 |
| 6 小时 | 875 W | 8.4 小时 | 3.8 小时 |
| 1 天 | 3500 W | 33 小时 | 15 小时 |
| 2 天 | 7000 W | 66 小时 | 30 小时 |
消费者最好跟分区数量一一对应,或分区数为消费者的倍数,例如 6 分区,三个消费者,这样每个消费者都能均衡的消费同等数量的分区。
最后决定历史主题创建 3 个分区,同时启用 3 个消费者进行消费。
消费者的资源消耗
启动多消费者后,EC2(c5.large)CPU 资源消耗增加,2核跑满,做了以下调整:
- 升级机型为 c5.xlarge (4核,8GB)
- 每次提交后 sleep 0.5 秒钟

积压消息情况下,消息处理能力为:540w / 小时。

无积压消息时,消息处理速度等于生产的速度。
指标的记录
首次接入 Kafka 应该添加监控指标,例如生产者推送消息数量,消费者处理的消费数量,Kafka 故障时服务端的失败提交数,协程池协程不足时,非阻塞调用的 Invoke 报错。进一步,Kafka 所在服务器的状态、磁盘使用情况都应该进行记录。
Kafka 服务重启会有报错
模拟 Kafka 宕机、重启等情形,Server 指标的变化。
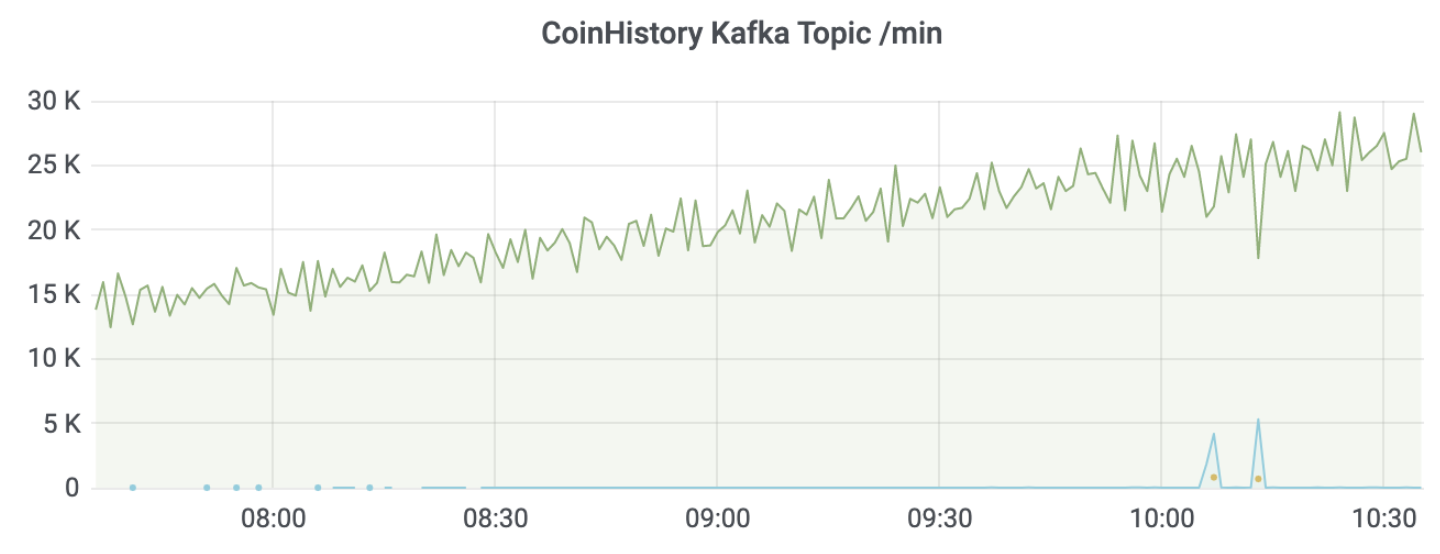
Invoke 调用失败次数
当协程不足时(最开始评估为 100 个),高峰段报错增多,低峰段无报错,将协池内协程数改为300后,报错消失。
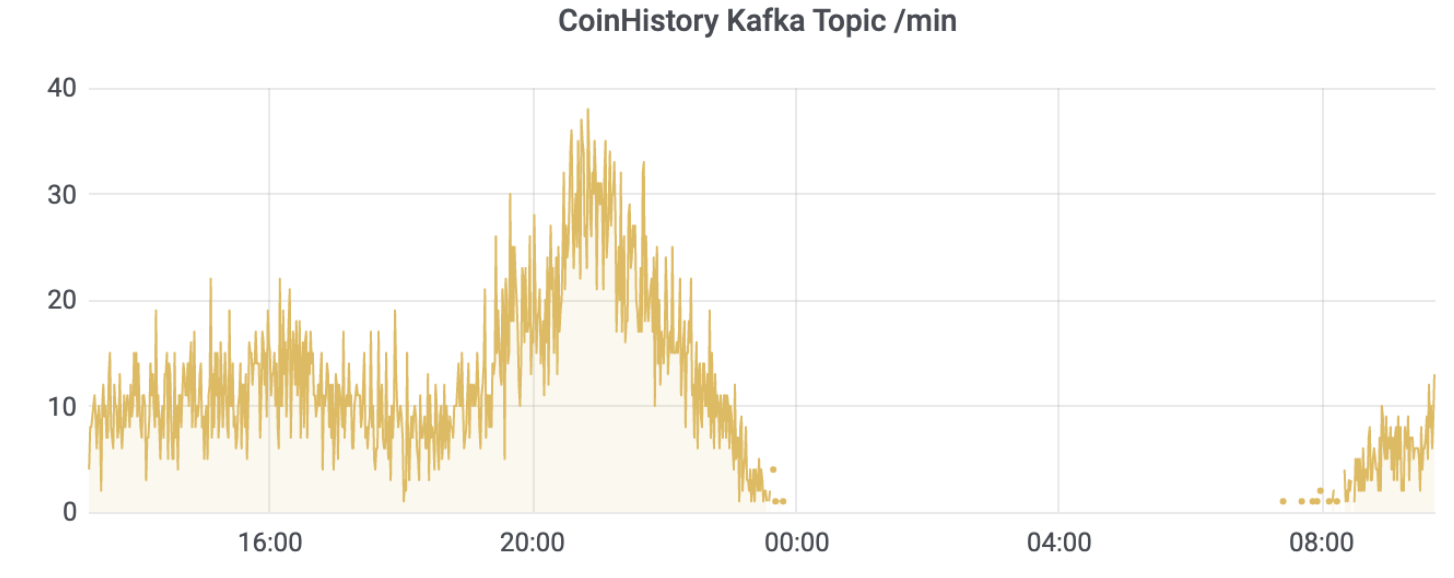
Kafka 磁盘占用评估
基于 history 历史统计估算(仅供参考,占用磁盘空间大小与单条数据量大小密切相关)
| 时间 | 磁盘消耗 | 数据来源 |
|---|---|---|
| 1 小时 | 500 MB | 准确值 |
| 1 天 | 3.7 GB | 准确值 |
| 3 天 | 11.1 GB | 估计值 |
| 7 天 | 25.9 | 估计值 |
上线效果
由 Kafka 队列缓冲,逐条写入改为 1000 条/次的批量写入后,CPU 负载下降 4 ~5%,目标达成。