Loki 是 Grafana 实验室开发的一个水平可扩展、高可用、多租户的日志聚合系统。LogQL(Log Query Language)是专门为 Loki 设计的用于查询日志条目的语言。
本文根据官方文档整理了 LogQL 语法示例,以作备忘。
简单 LogQL 示例
查询标签
{ filename="/var/log/syslog" }=相等!=不相等=~正则匹配!~正则不匹配
这是一些正则示例
{name =~ "mysql.+"}
{name !~ "mysql.+"}
{name !~ `mysql-\d+`}标签 + 包含字符
{filename="/var/log/syslog"} |= "Day"此处 “|” 是管道操作符号,将上一查询结果传递,等号这里同样支持相等、不等、正则。
{container="appserver"} |~ "Error | task.err" 以 Game Server 输出为例,首先过滤容器为 appserver 的日志,然后在这些日志中进一步过滤出包含 “ERROR” 或包含 “task.err” 的记录,包含的内容会高亮显示。
如果需要同时包含多个关键字,使用管道符多次过滤
{container="appserver"} |= "task.err" |= "unexpected end of JSON input"进一步,可以针对标签再进行过滤,此处添加了 “node_name = "ip-10-10-3-87.ec2.internal"”,表示记录的标签 node_name 需要为“ip-10-10-3-87.ec2.internal”,查看特定机器的日志。
{container="appserver"} |= "task.err" |= "unexpected end of JSON input" | node_name = "ip-10-10-3-87.ec2.internal"LogQL 语法结构总览
以上演示了基础示例,接下来系统的了解 LogQL 语法
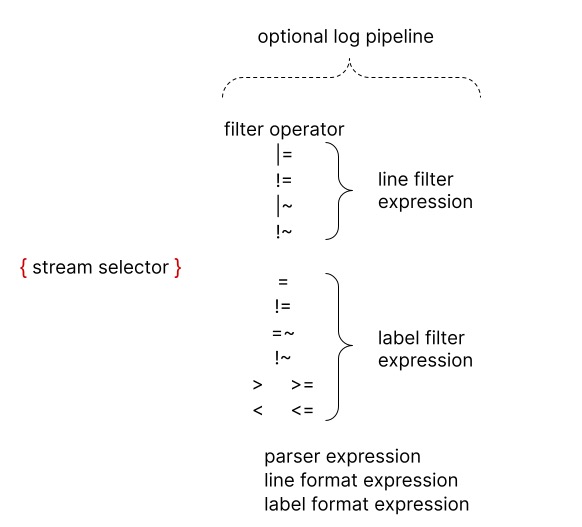
每个 LogQL 查询语句都必须包含一个流选择器(Stream Selector),即用 “{” 和 “}” 包裹的查询语句,其后跟随可选的 Log Pipeline 用于过滤。
如果按照类别划分,Log Pipeline 可以分为
- 过滤表达式:行过滤表达式(Line Filter Expression)和标签过滤表达式(Label Filter Expression)
- 解析表达式
- 格式化表达式
过滤表达式
过滤表达式在上文示例已经见过,= "task.err 即行过滤表达式,用于在流选择器选择日志流后,过滤关注日志,缩小后续处理范围,node_name = "ip-10-10-3-87.ec2.internal" 是标签过滤表达式,进一步缩小日志范围。
行过滤表达式
虽然行过滤器表达式可以放在日志管道中的任何位置,但最好在一开始就使用它们,将它们放在开头可以提高查询的性能,因为它只在行匹配时进行进一步处理,一旦应用了日志流选择器,行过滤器表达式是过滤日志的最快方式。
|=日志行包含字符串,如:|= "error"包含 “error” 字符串!=日志行不包含字符串,如:!= "type=ReplicaManager"不包含 "type=ReplicaManager" 字符串|~日志行匹配正则表达式!~日志行不匹配正则表达式
正则表达式示例可以参考 Line filter expression 章节官方文档
一个包含 “error”,但不包含 “timeout” 的过滤示例:
{job="mysql"} |= "error" != "timeout"标签过滤表达式
标签过滤表达式允许使用原始和提取的标签过滤日志行,它可以包含多个谓词。
支持多个比较符号及值类型,比如:
cluster="namespace"duration > 1mbytes_consumed > 20MBsize == 20kbduration >= 20ms or method="GET" and size <= 20KBduration >= 20ms or (method="GET" and size <= 20KB)
关于比较符号和值类型,详参 Label filter expression 官方文档。
补充说明:行和标签过滤器都支持 IP 规则进行过滤,详参 Matching IP addresses 章节。
解析表达式
解析表达式能从日志内容中解析出标签,例如一个 JSON Payload 日志行
{ "a.b": {c: "d"}, e: "f" }通过 JSON 解析器,能够解析出如下标签
a_b_c="d"
e="f"Loki 支持以下类型的解析器:
- json JSON 解析器
- logfmt 日志解析器
- pattern 模版解析器
- regexp 正则解析器
- unpack Pack 内容解析器
接下来对每个解析器进行说明和举例
JSON 解析器
有两种语法,不带参数的 | json 和带参数的 | json label="expression", another="expression" 解析器
先以不带参数的 json 解析器为例
{
"protocol": "HTTP/2.0",
"servers": ["129.0.1.1","10.2.1.3"],
"request": {
"time": "6.032",
"method": "GET",
"host": "foo.grafana.net",
"size": "55",
"headers": {
"Accept": "*/*",
"User-Agent": "curl/7.68.0"
}
},
"response": {
"status": 401,
"size": "228",
"latency_seconds": "6.031"
}
}会解析出标签
"protocol" => "HTTP/2.0"
"request_time" => "6.032"
"request_method" => "GET"
"request_host" => "foo.grafana.net"
"request_size" => "55"
"response_status" => "401"
"response_size" => "228"
"response_latency_seconds" => "6.031"⚠️ 注意事项:json 无参数解析器会忽略数组的处理,上例中的 servers 字段被忽略
使用带参数的 json 解析器(| json label="expression", another="expression")可以只从 JSON Payload 中解析出关注的字段标签
| json first_server="servers[0]", ua="request.headers[\"User-Agent\"]"以上表达式将从数据中解析出 servers[0] 并绑定 first_server 标签,request.headers[\"User-Agent\"] 绑定到 ua 标签。
"first_server" => "129.0.1.1"
"ua" => "curl/7.68.0"当 label 和 json field 名称相同时,可以省略 expression,即:| json servers 等效于 | json servers="servers"
logfmt 日志解析器
跟 json 解析器类似,logfmt 也分为有参数和无参数语法用来解析部分和全部数据。
logfmt 用于处理 https://brandur.org/logfmt 格式的日志数据

日志实例:
at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service=8ms status=200会解析出标签
"at" => "info"
"method" => "GET"
"path" => "/"
"host" => "grafana.net"
"fwd" => "124.133.124.161"
"service" => "8ms"
"status" => "200"其有参数使用方式为 | logfmt label="expression", another="expression"
以下表达式会提取 host 和 fwd 字段,其中 fwd 会被重命名为 fwd_ip 标签
| logfmt host, fwd_ip="fwd"作为了解,logfmt 支持两个参数 --strict 和 --keep-empty,前者可以进行更为严格的校验,默认的宽松模式当字段格式错误会忽略处理,开启严格模式后会报错停止解析。后者在无参数解析时会保留独立的键,值为空作为标签,有参数解析时只要选定了字段,则无需指定 --keep-empty 也会包含键值。
logfmt 使用示例
| logfmt --strict
| logfmt --strict host, fwd_ip="fwd"
| logfmt --keep-empty --strict hostpattern 模式解析器
支持自定义表达式从日志行显式提取字段。格式为:| pattern "<pattern-expression>"
以下以 Nginx 日志为例
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""这行日志可以被以下模式表达式解析
<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_> 解析出的标签如下
"ip" => "0.191.12.2"
"method" => "GET"
"uri" => "/api/plugins/versioncheck"
"status" => "200"
"size" => "2"
"agent" => "Go-http-client/2.0"模式表达式由两部分组成 —— 捕获和文字。
捕获是由 “<” 和 “>” 框选出的部分,例如
默认情况下,表达式从日志行的开始位置开始匹配,如果想要忽略部分起始内容,可以在开始处使用 <_>,以下是一个示例
level=debug ts=2021-06-10T09:24:13.472094048Z caller=logging.go:66 traceID=0568b66ad2d9294c msg="POST /loki/api/v1/push (204) 16.652862ms"使用表达式:<_> msg="
注意 ⚠️:
- 合法的 pattern 解析器至少包含一个命名的捕获
- 两个捕获之间至少应包含一个空白分隔,不能连在一起
regexp 正则解析器
与 json 和 logfmt 解析器不同,regexp 解析器必须携带参数,格式为:| regexp "
这里的正则表达式使用 golang/re2 进行解析,每个正则解析器都需要至少包含一个子匹配,例如:(?P
例如,表达式:
| regexp "(?P<method>\\w+) (?P<path>[\\w|/]+) \\((?P<status>\\d+?)\\) (?P<duration>.*)"应用于日志
POST /api/prom/api/v1/query_range (200) 1.5s将解析出标签
"method" => "POST"
"path" => "/api/prom/api/v1/query_range"
"status" => "200"
"duration" => "1.5s"能使用模式解析器时,建议优先使用模式解析器,因为正则表达式更难以编写和调试。
技巧
To avoid escaping special characters you can use the `(backtick) instead of " when quoting strings. For example
\w+is the same as "\w+". This is specially useful when writing a regular expression which contains multiple backslashes that require escaping.
unpack 解析器
跟 pack 搭配使用,使用 promtail 的 pack 步骤 将日志放入 _entry 后。
{
"container": "myapp",
"pod": "pod-3223f",
"_entry": "original log message"
}可以使用 unpack 解析器将日志的标签解析出来,上例中的 container 和 pod 标签,同时将特殊字段 _entry 中的内容替换为日志行,unpack 后通常搭配 json 和 logfmt 使用,进一步处理 "original log message"
Line format 表达式
使用 line_format 表达式可以重写日志。
它遵照 text/template 的模版格式,表达式结构如下
| line_format "{{.label_name}}"所有的标签都注入到模版中,可以在模版中使用,如以下示例
{container="frontend"} | logfmt | line_format "{{.query}} {{.duration}}"它重写日志结构,只包含 query 和 duration 标签的内容,如果需要编写复杂的模版,可以使用反撇号(backtick)代替双引号,避免语法报错
line_format 表达式支持 math 函数,例如有如下数据
ip=1.1.1.1, status=200 and duration=3000(ms)经由以下表达式处理
{container="frontend"} | logfmt | line_format "{{.ip}} {{.status}} {{div .duration 1000}}"日志将被格式化为以下内容
1.1.1.1 200 3标签格式化表达式
添加/修改标签
使用 | label_format 表达式可以重命名、修改、添加标签,支持逗号分隔符一次进行多个操作。
当等号两边都是标签时,dst=src 将把 src 标签重命名为 dst,当右侧为模版时,dst="{{.status}} {{.query}}" dst 标签内容值将被替换,如 dst 不存在则新建标签,这里的模版语法跟 line_format 支持的模版语法一致
如果不希望 dst=src 在赋值时销毁 src 标签,则可使用 dst="{{.src}}"
补充:不允许在一个表达式内对一个标签多次修改 | label_format foo=bar,foo="new" ⚠️
删除标签
删除标签关键字为 drop,语法为 |drop name, other_name, some_name="some_value"
示例数据
{"level": "info", "method": "GET", "path": "/", "host": "grafana.net", "status": "200"}表达式
{job="varlogs"} | json | drop level, method="GET"标签
"path" => "/"
"host" => "grafana.net"
"status" => "200"保留标签
| keep 表达式只会保留特定的标签,删除所有其它标签,语法为 |keep name, other_name, some_name="some_value"
示例数据
{"level": "info", "method": "GET", "path": "/", "host": "grafana.net", "status": "200"}
{"level": "info", "method": "POST", "path": "/", "host": "grafana.net", "status": "200"}表达式
{job="varlogs"} | json | keep level, method="GET"标签
level => "info"
method =>"GET"
{"level": "info", "method": "GET", "path": "/", "host": "grafana.net", "status": "200"}
level => "info"
{"level": "info", "method": "POST", "path": "/", "host": "grafana.net", "status": "200"}案例实践
有日志内容如下
2024-04-01T10:09:04.060Z ERROR task_scheduler/task_scheduler.go:54 task.err {"app_name": "mars", "server": "appserver", "name": "activity.update_remote_config", "err": "unexpected end of JSON input", "task_duration": "4.820625ms"}日志内容都包含在最后的 JSON Payload 中,以下使用两种方式解析到 JSON 内容,使其标签化
模式匹配
首先使用模式匹配,这是推荐且易用的方式,完成语句如下
{container="appserver"} |= "task.err" | pattern "<datatime>\t<log_level>\t<func>\t<msg>\t<json_payload>" | line_format "{{.json_payload}}" | json正则匹配
{container="appserver"} |= "task.err" |= "unexpected end of JSON input" | regexp "(?P<datatime>[^\\s]+)\\t(?P<level>[\\w]+)\\t(?P<func_line>[^\\s]+)\\t(?P<msg>[^\\s]+)\\t(?P<json_payload>.*)" | line_format "{{.json_payload}}" | json跟模式匹配的效果是一样的,根据 json 内容生成的标签如下

使用标签过滤
在以上的表达式基础上,可以针对标签再次进行过滤日志
| name = "rank.update_remote_config"过滤 json 内 name 字段值为 "rank.update_remote_config" 的数据。
