摘要
ES 学习了几天,还没透彻,组里有预研学习 Kafka 的需求,只好插队学习,久闻其名,正好了解。
与 RabbitMQ 对比
组长去年出去学习就说不少公司在用 Kafka,想要在项目中应用,我之前了解一点点 RabbitMQ 消息队列,就挺好奇很多公司为什么更侧重于使用 Kafka,而不是 RabbitMQ,它们肯定是有各自特点的,我在网上找了些它们的对比如下。
| Kafka | RabbitMQ | |
|---|---|---|
| 应用场景 | 用于处于活跃的流式数据,大数据量的数据处理上。 | 用于实时的,对可靠性要求较高的消息传递上。 |
| 架构模型 | 以 consumer 为中心,无消息的确认机制 | 以 broker 为中心,有消息的确认机制 |
| 吞吐量 | 消息处理的效率高,吞吐量高。 | 支持事务,不支持批量操作,吞吐量小。 |
| 集群负载均衡 | 采用 zookeeper 进行管理 | 本身不支持负载均衡 |
它们的特点还是很鲜明的,抛开支持功能的细节,Kafka 特点是分布式,适合于吞吐量高的场景,RabbitMQ 功能更加丰富,适合于对于消息可靠性,实时性,安全性更高的场景,如银行金融业。
于是近两年 Kafka 听的比较多就好解释了,因为很多公司的日志系统,分部署存储,数据需要流转,处理,分析,监控,所以大家选择了 Kafka,以适应大数据应用。
引用参考文章作者两句话,感觉很精髓:
RabbitMQ 在于 routing,而 Kafka 在于 streaming。
另一句
消息中间件大道至简:一发一存一消费,没有最好的消息中间件,只有最合适的消息中间件。
更详尽的文章链接:
一些概念
- Kafka 可以单机或集群部署。
- Kafka 使用主题(Topics)来分类记录(Record)。
- 每条消息包含一个键(Key),一个值(Value),还有时间戳。
- 数据存储分区块,这样的设计使得数据能分散在多个服务器,一个主题可以有多个分区,多分区也能支持并行处理。
- Kafka 会保留所有发布的记录,不管这个记录有没有被消费过。
- Kafka 的性能跟存储的数据量的大小无关, 所以将数据存储很长一段时间是没有问题的。
- 可以把 Kafka 认为是一种特殊用途的分布式文件系统,致力于高性能,低延迟的有保障的日志存储,能够备份和自我复制。
- 消费者来决定读取的偏移,即读出线性记录上的指定位置数据或跳到“最后”位置,接收最新记录。
- 生产者发布到主题的数据,Kafka可以根据规则存入不同的分区,跟关系型数据库表分区是相似的概念。
- 同分区内存储的消息,消费者读取记录,其顺序能够得到保证,在需要严格保证消息的消费顺序的场景下,需要将分区数目设为1。
- Kafka 消费群概念可以兼顾队列和发布-订阅模式的优点,可以像队列一样让消息被一组进程处理(一个消费群多个成员),也可以发送广播消息到多个消费群。
- 副本是分区的备份,只用来防止数据丢失,消费者不会从副本读取数据,如果副本异常,负责读写的“活动”分区会删除副本并重新创建。
Broker 摘自:Kafka简介
- Kafka 集群包含一个或多个服务器,服务器节点称为 broker。
- broker 存储 topic 的数据。如果某 topic 有N个 partition,集群有N个 broker,那么每个 broker 存储该 topic 的一个partition。
- 如果某 topic 有N个 partition,集群有(N+M)个 broker,那么其中有N个 broker 存储该 topic 的一个 partition,剩下的M个broker 不存储该 topic 的 partition 数据。
- 如果某 topic 有N个 partition,集群中 broker 数目少于N个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
接口分类
Kafka 提供的 API 有如下几个类别:
- 生产者API,允许应用程序发布记录流至一个或多个主题。
- 消费者API,允许应用程序订阅一个或多个主题,并处理这些主题接收到的记录流。
- Streams API,允许应用程序充当流处理器,从一个或多个主题接收记录流,处理后输出到一个或多个主题。
- Connector API,用于 Kafka 和其它系统进行数据传输工具,比如从数据库获取变更的数据。
使用案例
- 做为消息中间件,解耦数据的生产和消费,缓冲未处理的消息。
- 用于网站用户活动记录追踪。
- Metrics,用于监测应用数据程序输出内容以便产生数据用于订阅。
- 日志聚合,性能和时效性有保障。
- 流处理可以把抓取内容经过筛选,格式化后输出到主题以供应用程序使用。
部署
Kafka 依赖于 zookeeper 进行管理,需要首先进行安装。
docker pull wurstmeister/zookeeper启动容器
docker run -d --restart="always" --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper之后安装 Kafka
docker pull wurstmeister/kafka启动容器
docker run -d --restart=always --name kafka -p 9092:9092 -p 9988:9988 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.50.252:2181 -e JMX_PORT=9988 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.50.252:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /opt/etc/localtime:/etc/localtime wurstmeister/kafka参数含义
- KAFKA_BROKER_ID 在kafka集群中,每个 kafka 都有一个 BROKER_ID 来区分自己。
-
KAFKA_ZOOKEEPER_CONNECT 配置 zookeeper 管理 kafka 的路径,路径为 namespace,非必选项
-
KAFKA_ADVERTISED_LISTENERS 把 kafka 的地址端口注册给 zookeeper。
-
KAFKA_LISTENERS 配置 kafka 的监听端口。
先取消一个环境变量,因为这个环境变量会导致脚本报错。
unset JMX_PORT进入容器
docker exec -it kafka /bin/bash创建主题
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper 192.168.50.252:2181 --create --replication-factor 1 --partitions 1 --topic test
# Output:
Created topic test.查看主题
$KAFKA_HOME/bin/kafka-topics.sh --list --zookeeper 192.168.50.252:2181
# Output:
test主题详情
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper 192.168.50.252:2181 --describe --topic test输出内容
Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0删除主题
只是删除Topic在zk的元数据,日志数据仍需手动删除。
# 创建一个测试主题
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper 192.168.50.252:2181 --create --replication-factor 1 --partitions 1 --topic test2
# 标记删除主题
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper 192.168.50.252:2181 --delete --topic test2
# 查看主题列表
$KAFKA_HOME/bin/kafka-topics.sh --list --zookeeper 192.168.50.252:2181发送消息测试
启动生产者
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test新建一个终端,启动消费者
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning--from-beginning 参数是获取主题全部内容,如果不加这个参数那么它将只接收后续发布的消息。
现在在生产者中输入内容发送,消费者终端可以马上看到消息。
查看消费组/消费者
$KAFKA_HOME/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list输出内容
console-consumer-69271查看消费者
$KAFKA_HOME/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group console-consumer-69271 --describe输出内容
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-69271 test 0 - 203 - consumer-console-consumer-69271-1-f13edb36-d972-4637-acda-bf957e7c5ddd /172.17.0.1 consumer-console-consumer-69271-1整理一下是如下内容
| 列明 | 内容 |
|---|---|
| GROUP | console-consumer-69271 |
| TOPIC | test |
| PARTITION | 0 |
| CURRENT-OFFSET | - |
| LOG-END-OFFSET | 203 |
| LAG | - |
| CONSUMER-ID | consumer-console-consumer-69271-1-f13edb36-d972-4637-acda-bf957e7c5ddd |
| HOST | /172.17.0.1 |
| CLIENT-ID | consumer-console-consumer-69271-1 |
集群管理页面
获取镜像
docker pull solsson/kafka-manager启动容器
docker run -itd --name=kafka-manager -p 9000:9000 -e ZK_HOSTS="192.168.50.252:2181" solsson/kafka-manager访问:http://192.168.50.252:9000/
在管理页面可以添加集群,对集群主题等进行一些设置。
之前启动 Kafka 容器指定的 9988 端口就是用于 kafka-manager 的。
注意:这个图片里的 192.168.50.252/kafka => 192.168.50.252 更新文章时把命令空间参数去掉了。
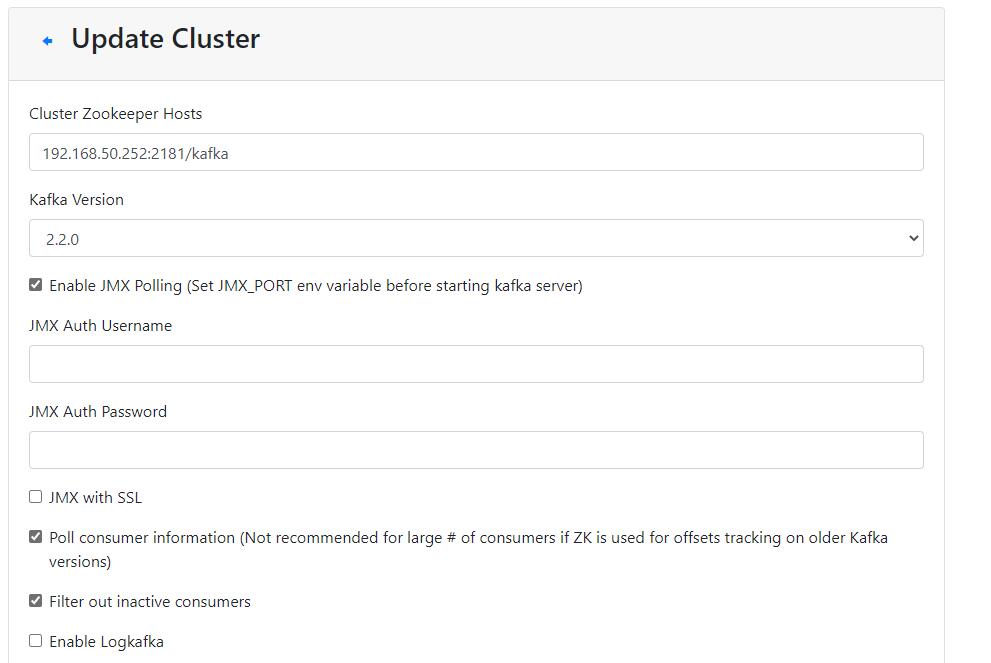
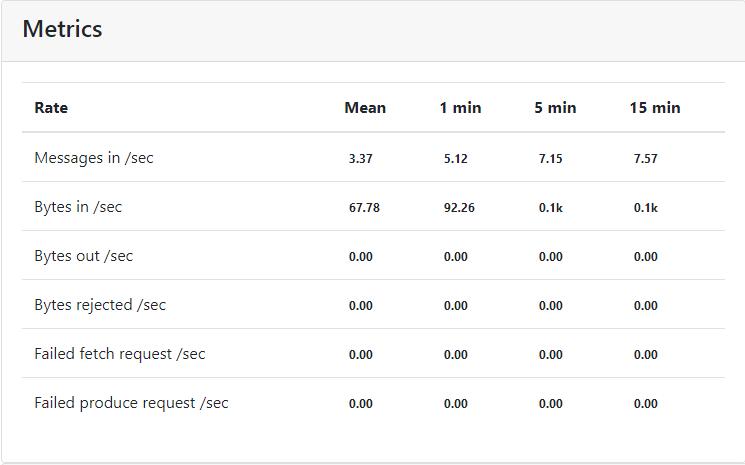
开启Poll consumer information 后有数据的速率显示。
那么 Kafka 最基础的知识暂时学习到这里。
参考