前段时间用 ChatGPT 问了不少问题,菜谱、脚本、起变量/模块名称,一直没有尝试用它来生成代码,刚好有个小需求,需要写 Python 脚本在两个数据库间同步数据,决定让 ChatGPT 试试
保存了对话的 HTML
我使用了 Chrone 扩展 SingleFile,将与 ChatGPT 网页版的对话保存为 html 格式,便于查阅,你可以点击链接查看本次聊天,排版的效果比本文粘贴的要好。
链接地址:ChatGPT_2023_2_23_18_05_13.html
生成建表语句与更新 SQL
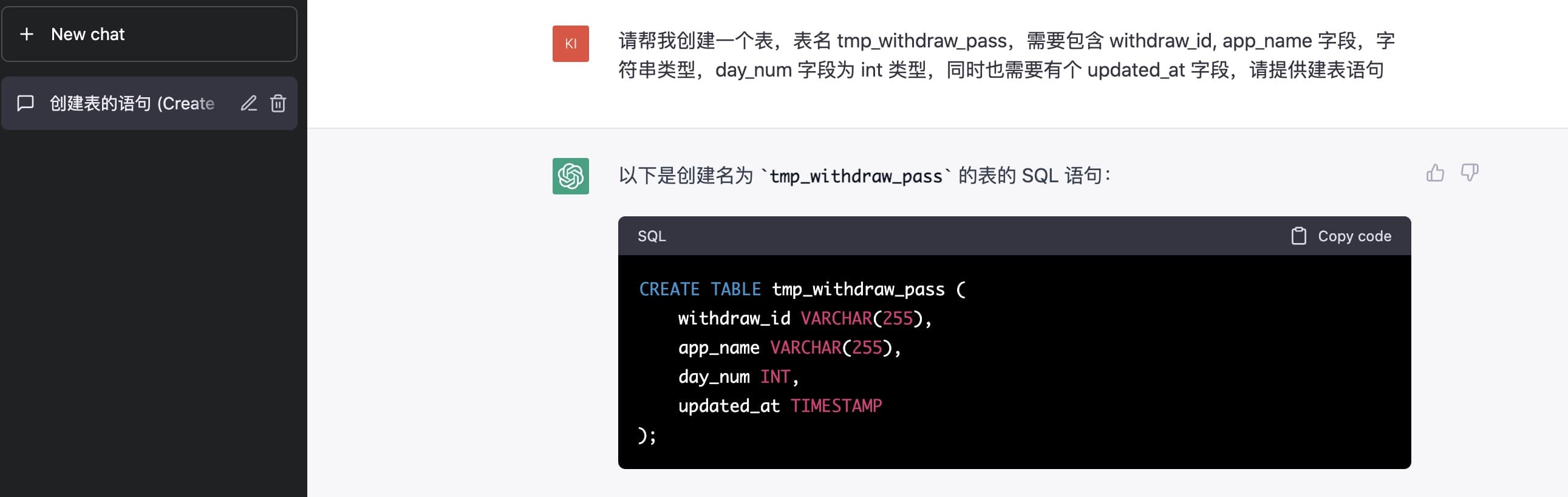
我:请帮我创建一个表,表名 tmp_withdraw_pass,需要包含 withdraw_id, app_name 字段,字符串类型,day_num 字段为 int 类型,同时也需要有个 updated_at 字段,请提供建表语句
ChatGPT:以下是创建名为 tmp_withdraw_pass 的表的 SQL 语句:
CREATE TABLE tmp_withdraw_pass (
withdraw_id VARCHAR(255),
app_name VARCHAR(255),
day_num INT,
updated_at TIMESTAMP
);因为没有限定 PostgreSQL 数据,于是追加补充
我:建表语句需要支持 postgresql
ChatGPT:如果您需要在 PostgreSQL 数据库中创建该表,请使用以下 SQL 语句:
CREATE TABLE tmp_withdraw_pass (
withdraw_id VARCHAR(255),
app_name VARCHAR(255),
day_num INTEGER,
updated_at TIMESTAMP
);我本来计划,在同步数据到表中后,通过 SQL 来更新 day_num 序号,使其达到效果如下(如 20 条数据,分成 10 组,那么每组有两条数据)
id001, appname01, 1, 2023-02-23
id002, appname01, 1, 2023-02-23
id003, appname01, 2, 2023-02-23
id004, appname01, 2, 2023-02-23
...
id019, appname01, 10, 2023-02-23
id020, appname01, 10, 2023-02-23于是问 AI
我:基于以上 tmp_withdraw_pass 表,请帮我写个 sql,它负责 set 更新表中的 day_num 字段,数据均分成十份,更新后,day_num 字段的内容第一份为 1,第二份为 2,第三份为 3,以此类推,你需要根据 withdraw_id 排序后再分段
它回复到
ChatGPT:以下是一个 SQL 查询语句,用于将 tmp_withdraw_pass 表中的 day_num 字段平均分成十份并进行更新。更新后,第一组记录 day_num 字段的值为 1,第二组为 2,以此类推。在更新之前,该查询会首先根据 withdraw_id 字段进行排序,然后再按顺序将记录分成十个相等的部分。
WITH sorted_withdrawals AS (
SELECT withdraw_id, app_name, day_num, updated_at,
ROW_NUMBER() OVER (ORDER BY withdraw_id) as row_num,
COUNT(*) OVER() as total_count
FROM tmp_withdraw_pass
),
updated_withdrawals AS (
SELECT withdraw_id, app_name,
CEIL(row_num * 10.0 / total_count) AS new_day_num,
updated_at
FROM sorted_withdrawals
)
UPDATE tmp_withdraw_pass
SET day_num = u.new_day_num
FROM updated_withdrawals u
WHERE tmp_withdraw_pass.withdraw_id = u.withdraw_id;核对代码发现我没有表述数据应该根据 app_name 分组更新,于是补充如下
我:在你提供的 sql 基础上,请改写 sql,使其按 app_name 分组,不同 app_name 互不影响
ChatGPT: 以下是一个改写后的 SQL 查询语句,它在按 app_name 字段进行分组的基础上,将 day_num 字段平均分成十份并进行更新。更新后,第一组记录 day_num 字段的值为 1,第二组为 2,以此类推。在更新之前,该查询会首先根据 withdraw_id 字段进行排序,然后再按顺序将记录分成十个相等的部分。
WITH sorted_withdrawals AS (
SELECT withdraw_id, app_name, day_num, updated_at,
ROW_NUMBER() OVER (PARTITION BY app_name ORDER BY withdraw_id) as row_num,
COUNT(*) OVER(PARTITION BY app_name) as total_count
FROM tmp_withdraw_pass
),
updated_withdrawals AS (
SELECT withdraw_id, app_name,
CEIL(row_num * 10.0 / total_count) AS new_day_num,
updated_at
FROM sorted_withdrawals
)
UPDATE tmp_withdraw_pass
SET day_num = u.new_day_num
FROM updated_withdrawals u
WHERE tmp_withdraw_pass.withdraw_id = u.withdraw_id
AND tmp_withdraw_pass.app_name = u.app_name;于是我得到了一个 SQL 脚本,可以将表中的数据分组标号,经过测试运行没有问题,AI 理解自然语言的能力和生成代码的能力可见一斑。
生成 Python 脚本
我:请提供给我一个 python 脚本,它的作用是连接数据库实例 A 的 withdraw_record 表,从中查询出 status = '' 的数据,插入到数据库 B 的 tmp_withdraw_pass 表中,withdraw_record 表包含 wirdraw_id, status, updated 等字段,tmp_withdraw_pass 表包含 wirdraw_id, app_name, day_num, updated_at 字段,脚本需要使用 psycopg2 库,同步数据需要支持循环,因为会从多张 withdraw_record 表同步数据到 tmp_withdraw_pass 表,app_name 是不同的
ChatGPT:下面是一个使用 psycopg2 库编写的 Python 脚本,它的作用是从数据库 A 的多张 withdraw_record 表中查询出 status 字段为 '' 的记录,并将这些记录插入到数据库 B 的 tmp_withdraw_pass 表中。在这个脚本中,我们将 withdraw_record 表分别映射到 app_name 值,通过循环遍历不同的 app_name 值,从相应的 withdraw_record 表中读取数据,然后将它们插入到 tmp_withdraw_pass 表中。
import psycopg2
# 数据库 A 的连接信息
A_DB_HOST = 'localhost'
A_DB_NAME = 'database_a'
A_DB_USER = 'user_a'
A_DB_PASSWORD = 'password_a'
# 数据库 B 的连接信息
B_DB_HOST = 'localhost'
B_DB_NAME = 'database_b'
B_DB_USER = 'user_b'
B_DB_PASSWORD = 'password_b'
# 各个 app_name 对应的 withdraw_record 表名
WITHDRAW_RECORD_TABLES = {
'app_name_1': 'withdraw_record_1',
'app_name_2': 'withdraw_record_2',
'app_name_3': 'withdraw_record_3',
# ...
}
# 连接数据库 A 和 B
a_conn = psycopg2.connect(host=A_DB_HOST, dbname=A_DB_NAME, user=A_DB_USER, password=A_DB_PASSWORD)
b_conn = psycopg2.connect(host=B_DB_HOST, dbname=B_DB_NAME, user=B_DB_USER, password=B_DB_PASSWORD)
# 循环遍历不同的 app_name 值
for app_name, table_name in WITHDRAW_RECORD_TABLES.items():
# 从数据库 A 中查询符合条件的记录
with a_conn.cursor() as a_cur:
a_cur.execute(f"SELECT withdraw_id, updated FROM {table_name} WHERE status = ''")
records = a_cur.fetchall()
# 将记录插入到数据库 B 的 tmp_withdraw_pass 表中
with b_conn.cursor() as b_cur:
for withdraw_id, updated in records:
b_cur.execute(
"INSERT INTO tmp_withdraw_pass (withdraw_id, app_name, day_num, updated_at) "
"VALUES (%s, %s, %s, %s)",
(withdraw_id, app_name, 0, updated)
)
# 提交事务
b_conn.commit()
# 关闭数据库连接
a_conn.close()
b_conn.close()接下来是不断的优化代码环节
我:请重新生成,因为数据库实例 A 上的 dbname 是不同的,表名则是相同的,表名都是 withdraw_record
ChatGPT: 好的,如果数据库实例 A 上的 dbname 不同,但是表名相同,那么可以将 WITHDRAW_RECORD_TABLES 字典改为只包含表名即可,如下所示:
import psycopg2
# 数据库 A 的连接信息
A_DB_HOST = 'localhost'
A_DB_NAME = 'database_a'
A_DB_USER = 'user_a'
A_DB_PASSWORD = 'password_a'
# 数据库 B 的连接信息
B_DB_HOST = 'localhost'
B_DB_NAME = 'database_b'
B_DB_USER = 'user_b'
B_DB_PASSWORD = 'password_b'
# 需要同步的表名
WITHDRAW_RECORD_TABLES = [
'withdraw_record',
# ...
]
# 连接数据库 A 和 B
a_conn = psycopg2.connect(host=A_DB_HOST, dbname=A_DB_NAME, user=A_DB_USER, password=A_DB_PASSWORD)
b_conn = psycopg2.connect(host=B_DB_HOST, dbname=B_DB_NAME, user=B_DB_USER, password=B_DB_PASSWORD)
# 循环遍历不同的表名
for table_name in WITHDRAW_RECORD_TABLES:
# 从数据库 A 中查询符合条件的记录
with a_conn.cursor() as a_cur:
a_cur.execute(f"SELECT withdraw_id, updated FROM {table_name} WHERE status = ''")
records = a_cur.fetchall()
# 将记录插入到数据库 B 的 tmp_withdraw_pass 表中
with b_conn.cursor() as b_cur:
for withdraw_id, updated in records:
b_cur.execute(
"INSERT INTO tmp_withdraw_pass (withdraw_id, app_name, day_num, updated_at) "
"VALUES (%s, %s, %s, %s)",
(withdraw_id, table_name, 0, updated)
)
# 提交事务
b_conn.commit()
# 关闭数据库连接
a_conn.close()
b_conn.close()生成跟预期不对,再引导一下
我:因为是从 A 同步多个不同 db 的 withdraw_record 表到 B 实例,所以 A_DB_NAME 需要从循环中获取,同样 a_conn 也应该在循环中
ChatGPT:好的,如果需要从 A 实例同步多个不同数据库的 withdraw_record 表到 B 实例,那么可以按照以下方式编写 Python 脚本:
import psycopg2
# 数据库 A 的连接信息
A_DB_HOST = 'localhost'
A_DB_USER = 'user_a'
A_DB_PASSWORD = 'password_a'
# 数据库 B 的连接信息
B_DB_HOST = 'localhost'
B_DB_USER = 'user_b'
B_DB_PASSWORD = 'password_b'
# 需要同步的数据库名和表名
WITHDRAW_RECORD_TABLES = {
'database_a1': 'withdraw_record',
'database_a2': 'withdraw_record',
# ...
}
# 连接数据库 B
b_conn = psycopg2.connect(host=B_DB_HOST, user=B_DB_USER, password=B_DB_PASSWORD)
# 循环遍历不同的数据库和表名
for a_db_name, table_name in WITHDRAW_RECORD_TABLES.items():
# 连接数据库 A
a_conn = psycopg2.connect(host=A_DB_HOST, dbname=a_db_name, user=A_DB_USER, password=A_DB_PASSWORD)
# 从数据库 A 中查询符合条件的记录
with a_conn.cursor() as a_cur:
a_cur.execute(f"SELECT withdraw_id, updated FROM {table_name} WHERE status = ''")
records = a_cur.fetchall()
# 将记录插入到数据库 B 的 tmp_withdraw_pass 表中
with b_conn.cursor() as b_cur:
for withdraw_id, updated in records:
b_cur.execute(
"INSERT INTO tmp_withdraw_pass (withdraw_id, app_name, day_num, updated_at) "
"VALUES (%s, %s, %s, %s)",
(withdraw_id, table_name, 0, updated)
)
# 提交事务
b_conn.commit()
# 关闭数据库连接
a_conn.close()
# 关闭数据库连接
b_conn.close()可以直接提供给它示例代码,有了更清晰的提示,AI 生成的代码会更符合预期。
我:因为表名都叫 withdraw_record,可以用变量存储表名,同时可以定义数组来存储 dbname,例如: WITHDRAW_RECORD_TABLES = ["database_a1", "database_a2"]
ChatGPT:好的,如果多个数据库中的表名都是 withdraw_record,那么可以按照以下方式修改 Python 脚本:
import psycopg2
# 数据库 A 的连接信息
A_DB_HOST = 'localhost'
A_DB_USER = 'user_a'
A_DB_PASSWORD = 'password_a'
# 数据库 B 的连接信息
B_DB_HOST = 'localhost'
B_DB_USER = 'user_b'
B_DB_PASSWORD = 'password_b'
# 需要同步的数据库名
WITHDRAW_RECORD_DB_NAMES = [
'database_a1',
'database_a2',
# ...
]
# 表名
TABLE_NAME = 'withdraw_record'
# 连接数据库 B
b_conn = psycopg2.connect(host=B_DB_HOST, user=B_DB_USER, password=B_DB_PASSWORD)
# 循环遍历不同的数据库名
for a_db_name in WITHDRAW_RECORD_DB_NAMES:
# 连接数据库 A
a_conn = psycopg2.connect(host=A_DB_HOST, dbname=a_db_name, user=A_DB_USER, password=A_DB_PASSWORD)
# 从数据库 A 中查询符合条件的记录
with a_conn.cursor() as a_cur:
a_cur.execute(f"SELECT withdraw_id, updated FROM {TABLE_NAME} WHERE status = ''")
records = a_cur.fetchall()
# 将记录插入到数据库 B 的 tmp_withdraw_pass 表中
with b_conn.cursor() as b_cur:
for withdraw_id, updated in records:
b_cur.execute(
"INSERT INTO tmp_withdraw_pass (withdraw_id, app_name, day_num, updated_at) "
"VALUES (%s, %s, %s, %s)",
(withdraw_id, a_db_name, 0, updated)
)
# 提交事务
b_conn.commit()
# 关闭数据库连接
a_conn.close()
# 关闭数据库连接
b_conn.close()此时代码已较为符合预期,我又给 AI 提了一些建议
我:你可以修改 TABLE_NAME 为 A_TABLE_NAME,同时用 B_TABLE_NAME 存储 tmp_withdraw_pass 吗
我:b_conn 不用放在循环中初始化,因为它不会受到 A_DB_NAME 影响
我:b_cursor 也可以移动到循环外面
本次生成有个小惊喜,本来计划同步数据到临时表后再通过之前得来的 SQL 执行更新
没想到最后生成的代码 day_num = (i // (len(results) // 10)) + 1 达到了同样的效果
import psycopg2
A_DB_NAMES = ["database_a1", "database_a2"]
A_TABLE_NAME = "withdraw_record"
B_DB_NAME = "database_b"
B_TABLE_NAME = "tmp_withdraw_pass"
# 数据库 A 连接信息
A_HOST = "host"
A_PORT = "port"
A_USER = "user"
A_PASSWORD = "password"
# 数据库 B 连接信息
B_HOST = "host"
B_PORT = "port"
B_USER = "user"
B_PASSWORD = "password"
# 连接数据库 B
b_conn = psycopg2.connect(
dbname=B_DB_NAME,
user=B_USER,
password=B_PASSWORD,
host=B_HOST,
port=B_PORT
)
# 初始化 b_cursor
b_cursor = b_conn.cursor()
def sync_withdraw_record():
# 遍历 A_DB_NAMES
for A_DB_NAME in A_DB_NAMES:
# 连接数据库 A
a_conn = psycopg2.connect(
dbname=A_DB_NAME,
user=A_USER,
password=A_PASSWORD,
host=A_HOST,
port=A_PORT
)
a_cursor = a_conn.cursor()
# 查询 withdraw_id 和 updated_at 字段
select_sql = f"SELECT withdraw_id, updated_at FROM {A_TABLE_NAME} WHERE status = ''"
a_cursor.execute(select_sql)
results = a_cursor.fetchall()
# 关闭数据库 A 连接
a_cursor.close()
a_conn.close()
# 遍历结果集,插入到数据库 B 的 tmp_withdraw_pass 表中
for i, result in enumerate(results):
withdraw_id, updated_at = result
day_num = (i // (len(results) // 10)) + 1
app_name = A_DB_NAME
insert_sql = f"INSERT INTO {B_TABLE_NAME} (withdraw_id, app_name, day_num, updated_at) VALUES (%s, %s, %s, %s)"
b_cursor.execute(insert_sql, (withdraw_id, app_name, day_num, updated_at))
# 提交事务
b_conn.commit()
# 关闭 b_cursor
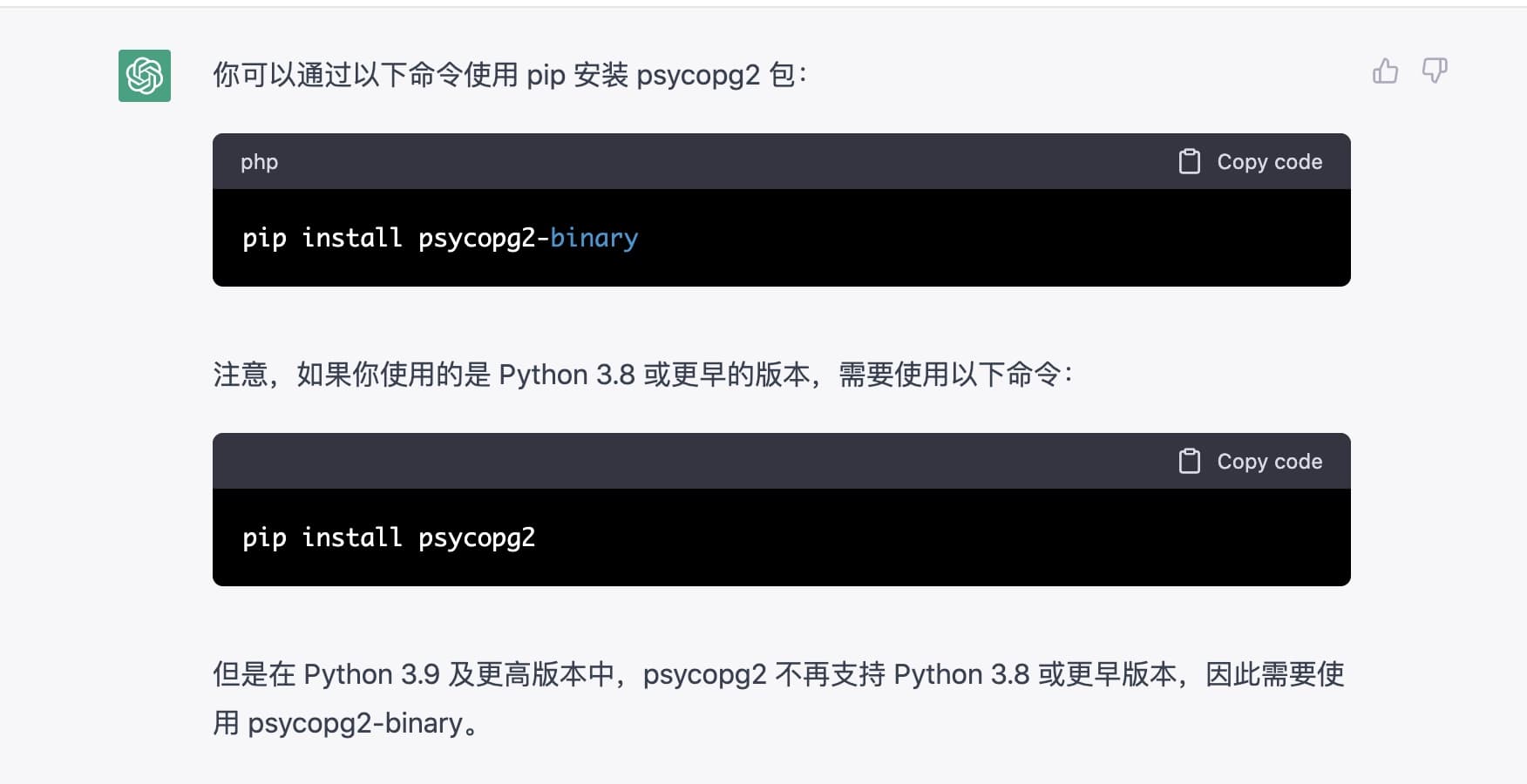
b_cursor.close()最后我问了 psycopg2 如何安装,ChatGPT 再次给出完善的答案
一些感想
之前一直以为 AI 是人工智障,ChatGPT 也感觉就是替代 Google 手动检索,但深入体验后,感觉有些震撼,它在自然语言的理解上,已比普通人强太多,同时在写代码这件事儿上,也会比绝大部分熟练技术工更优秀。
未来的 Web,App 等开发可能只需动动嘴,描述你的需求,AI 就能自动生成代码、构建、产出一个可用产品,并且随着你的表述,持续调整,直到你满意为止。(突然想到老罗的 TNT...
现在基于 AI 的大量应用还在探索,相信过不了两年,将会有一场新的风暴席卷各行各业。
—— 新挑战,新机遇,面对疾风吧